Definition
Die partielle Korrelation ist die bivariate Korrelation zweier Variablen, welche mittels linearer Regression vom Einfluss einer Drittvariablen bereinigt wurden (Bortz & Schuster, 2010, S. 340)
Einführung in partielle Korrelationen
Die partielle Korrelation soll anhand eines Beispiels veranschaulicht werden, wir betrachten dazu den Datensatz Icecream aus dem 📦 Ecdat-Package zum Eiskonsum (Hildreth & John, 1960).
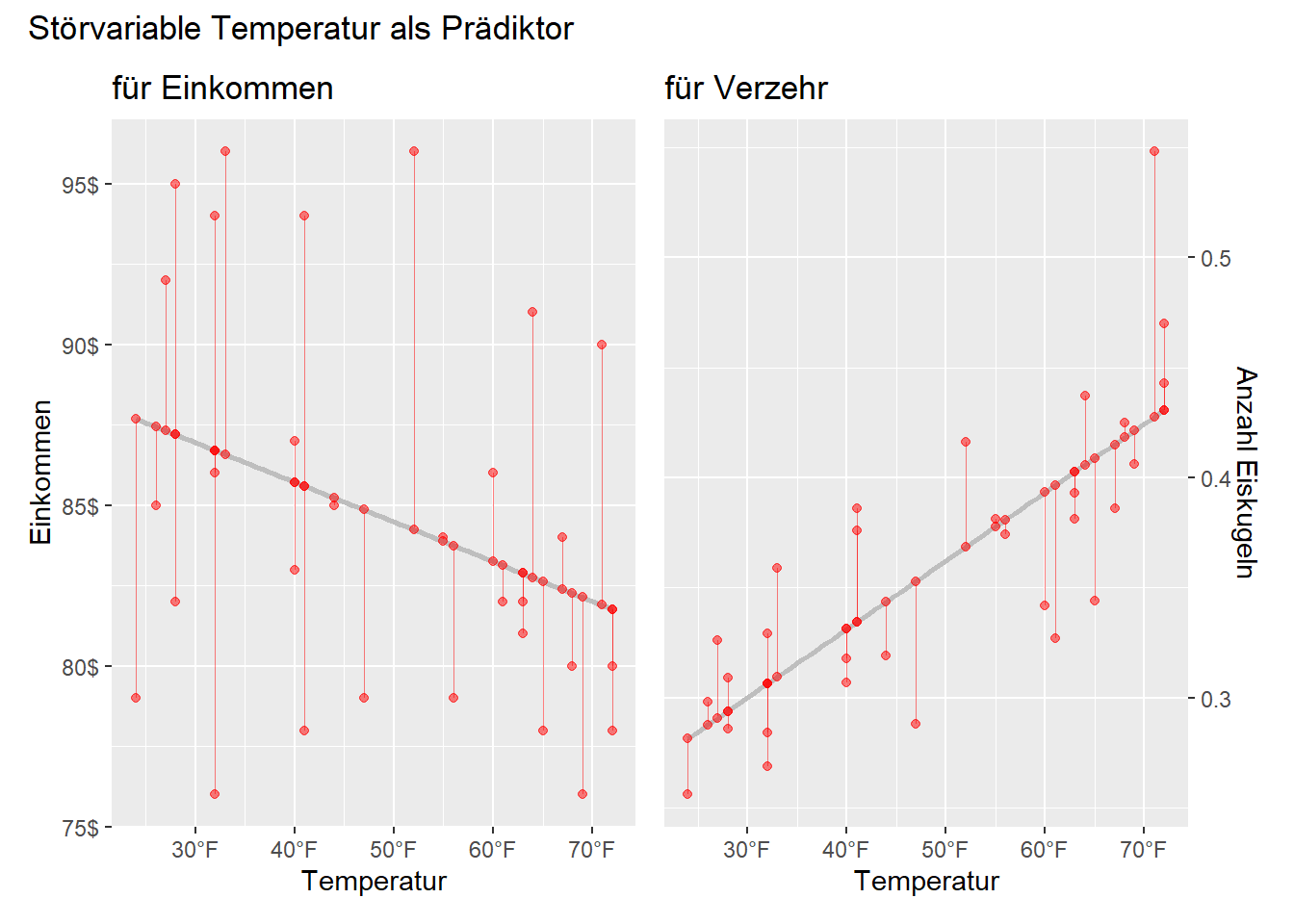
Dabei nehmen wir an, dass der Preis pro Kugel Eis über den gemessenen Zeitraum weitestgehend stabil ist. Gemessen wird der durchschnittliche Eiskonsum (cons: \(x_0 :=\) mittlerer Eiskugelverzehr pro Kopf) sowie das durchschnittliche Einkommen (income: \(x_1:=\) mittleres wöchentliches Einkommen pro Haushalt in Dolar). Wir nehmen an, dass Familien mit höherem Einkommen mehr Eis konsumieren (respektive deren Kinder). Diese Korrelation ist mit \(r_{01}=.05\), \(KI_{95\%}(-.32, .40)\) so extrem gering, dass sie sich nicht von null unterscheidet, \(t(28)=0.25\), \(p=.80\). Aus heutiger Sicht mag das nicht verwunderlich erscheinen, für das Jahr 1960 wäre aber die oben getestete Hypothese nicht unplausibel gewesen.
Allerdings wirken auch weitere Variablen auf den Eiskonsum ein, z. B. die vorherschende Temperatur (temp: \(x_2\) gemessen in Fahrenheit). So wird bei höheren Temerperaturen signifikant mehr Eis konsumiert, als bei niedrigen, \(r_{02}=.78\), \(KI_{95\%}(.58, .89)\). Dass Temperatur und Einkommen korreliert sind, ist zwar eher unplausibel, muss jedoch trotzdem berücksichtigt werden (z. B. bei saisonalen Arbeiten anzunehmen). Für die vorliegenden Daten zeigt sich eine geringe Korrelation, \(r_{12}=-.32\), \(KI_{95\%}(-.61, .04)\).
In R lassen sich die genannten Korrelationen schnell berechnen:
Wollen wir nun den Einfluss der Temperatur berücksichtigen, so gibt es zwei Möglichkeiten: A. die Temperatur konstant halten: klimatisch schwierig, aber wir könnten nur Messungen einer konstanten Temperatur miteinbeziehen. Oder B. den Einfluss der Temperatur herausrechnen aka. herauspartialisieren.
Da wir auf die vorliegenden Messwerte beschränkt sind, betrachten wir Option B., die auf der Regression aufbaut.
Werte mittels Regression bereinigen
In der einfachen linearen Regression wird eine Variable (Kriterium) durch einen Prädiktor vorhergesagt, wobei der Prädiktor mehr oder weniger mit dem Kriterium korreliert. I.d.R. ist diese Korrelation nicht \(\rho=1\), d.h. die Vorhersage nicht perfekt, wobei wir bei bekannten Werten die Residuen berechnen können als eben jene Differenz zwischen Vorhersage und wahren bzw. vorliegenden Werten.
Sagen wir jetzt eine der beiden Variablen unserer Korrelation \(r_{01}\) durch die Drittvariable vorher, z. B. Einkommen durch Temperatur. Dann erklärt Termperatur einen Teil der Varianz von Einkommen. Die verbleibenden Residuen haben aber zwangsläufig nichts mehr mit der Temperatur gemein, d.h. dieser überbleibende Teil stellt die bereinigte Variable dar. Gleiches machen wir mit der Variable Eisverzehr. Die Residuen (bereinigten Werte) sind in folgender Abbildung rot dargestellt. Haben wir die Residuen berechnet, müssen wir diese bereinigten Variablen nur noch korrelieren und erhalten eine bereinigte Korrelation.
In R können wir die Residuen eines Modells einfach berechnen.
Die neue Korrelation berechnen wir dann wie gehabt:
df_ice %$% cor(cons_star, income_star) [1] 0.5021635Es ergibt sich ein korrigiertes \(r_{01}^*=.50\). Die Notation mit dem Stern verdeutlicht, dass es sich hier nicht um die unbereinigte Korrelation \(r_{01}=.05\) handelt. Die Gegenüberstellung beider Werte verdeutlicht, dass der Effekt des Einkommens sich erst zeigt, wenn für Temperatur kontrolliert wird. Anstatt Kontrollieren sagt man hier auch von Herauspartialisieren, da die Anteile der Drittvariablen nicht mit in die partielle Korrelation eingehen.
partielle Korrelation über Formel/Funktion berechnen
Alternativ zum dargestellten Vorgehen kann die partielle Korrelation auch mit folgender Formel direkt berechnet werden:
\[ r_{(x_1x_2)/u} = \frac{r_{x_1x_2}-r_{x_1u}\times r_{x_2u}} {\sqrt{1-r_{x_1u}^2}\sqrt{1-r_{x_2u}^2}} \]
Dabei ist \(u\) jene Variable, die herauspartialisiert werden soll. Setzen wir die anfangs (oben) angegebenen Korrelationen ein, so ergibt sich auch hier ein \(r_{01}^*=.50\). In R können natürlich die berechneten Korrelationen eingesetzt werdern:
Alternaitv existiert aber im 📦 ppcor bereits die Funktion pcor.test:
df_ice %$% ppcor::pcor.test(cons, income, temp) estimate p.value statistic n gp Method
1 0.5021635 0.005506271 3.017346 30 1 pearsonDabei wird direkt die Test-Statistik samt p-Wert ausgegeben, im vorliegenden Beispiel unterscheidet sich die Korrelation \(r_{01}^*=.50\) signifikant, \(t(27), = 3.02\), \(p < .01\).
Pakete
Wir nutzen eine Reihe von Paketen für
- das Einlesen von SPSS Daten (📦
haven) - das Pfadmanagement in Projekten (📦
here) - die Datenaufbereitung (📦
magrittr,dplyr,tidyr) - die Visualisierung (📦
ggplot2) - die Darstellung des Outputs, insbesondere Tabellen (📦
rmarkdown,gt,DiagrammeR,knitr,kableExtra,downlit)1 - den Umgang mit Dataframes (📦
tibble) - das Konvertieren von statistischen Outputs in Tibbles (📦
broom) - die Berechnung von (Semi-)partiellen Korrelationen (📦
corrr,ppcor)2
Übungsaufgaben
Daten einlesen
Mit der read_sav()-Funktion aus dem 📦 haven-Paket lassen sich die Daten einlesen. Da haven das Variablenformat als Attribute speichert und diese uns bei der späteren Modellierung behindern, entfernen wir diese mit der zap_formats()-Funktion (vgl. dazu auch die Datenstruktur str(df_1) mit vs. ohne Anwendung der zap-Funktion). Schließlich fügen wir noch eine Personen-ID hinzu.
df_1 <- read_sav(here("data", "partiell", "daten.sav")) %>%
haven::zap_formats() %>%
tibble()
df_1 %>% gt_preview(top_n = 2) %>%
cols_align(align = "center",
columns = everything()) %>%
tab_stubhead(label = "Person") %>%
tab_options(table.width = px(100))| Person | x0 | x1 | x2 |
|---|---|---|---|
| 1 | 3 | 1 | 1 |
| 2 | 5 | 2 | 4 |
| 3..11 | |||
| 12 | 8 | 7 | 8 |
Visualisierung
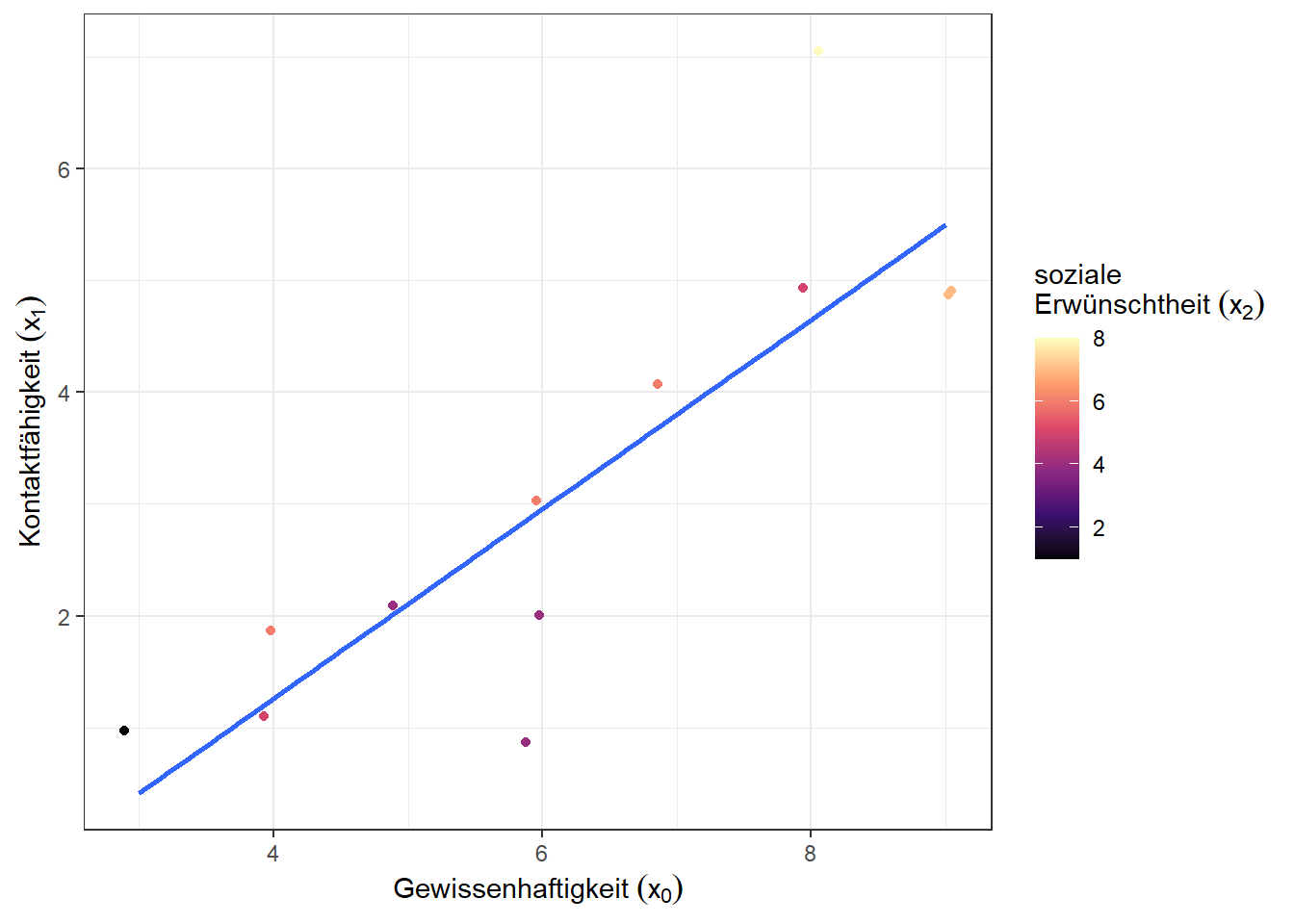
Bevor wir mit der eigentlichen Aufgabe beginnen, visualisieren die Daten mit einem Streudiagramm (Scatter-Plot), wobei wir die Variable soziale Erwünschtheit als Farbskala einbeziehen:
Teilaufgabe a
Korrelationen lassen sich mit der Base-R Funktion cor() berechnen. Für eine Matrix/Dataframe als Input werdeb die Korrelationen aller möglichen Dupel berechnet. Das Output ist entspechend eine Korrelationsmatrix M:
cor(df_1)| term | x0 | x1 | x2 |
|---|---|---|---|
| x0 | — | — | — |
| x1 | .85 | — | — |
| x2 | .71 | .77 | — |
Für das Einsetzen der Werte in eine Formel (s.u.) können zwei Vektoren x und y in cor(x, y) gegeben werden und das Output (eine Zahl \(r_{xy}\)) einer entsprechenden Variable zugewiesen werden:
- In der oberen Menu-Leiste Klick auf Analysieren
- im Dropdownmenu Korrelation ➡️ Bivariat auswählen
- die drei Variablen
x0,x1,x2markieren und mit Klick auf ↪️ zu Variablen hinzufügen - im Abschnitt Korrelationskoeffizienten die Option ☑️ Pearson anwählen
- mit Klick auf 🆗 bestätigen oder besser auf Einfügen klicken und die Synatax ausführen
Alternativ kann die folgende Synatax verwendet werden:
CORRELATIONS
/VARIABLES=x0 x1 x2
/PRINT=TWOTAIL NOSIG FULL
/MISSING=PAIRWISE.Teilaufgabe b
M.E. ist die nachfolgende Notation deutlich übersichtlicher, da jene Variable, die herauspartialisiert werden soll, eine saliente Benennung erhält. Man spricht
die partielle Korrelation von \(X\) und \(Y\) unter \(U\) ist gegeben durch:
\[ r_{(X,Y)/U} = \frac{r_{X,Y}-r_{X,U}\times r_{Y,U}} {\sqrt{1-r_{XU}^2}\sqrt{1-r_{YU}^2}} \]
Die partielle Korrelation kann mit R “händisch” wie folgt berechnet werden:
Die Formel können wir jedoch auch leicht in eine eigene Funktion verwandeln, in welche wir dann nur noch die drei Korrelationswerte einsetzen müssen:
Setzten wir die Korrelationswerte in die Funktion ein, kommen wir zum gleichen Ergebnis:
cor_part(r_01, r_02, r_12)[1] 0.6809885Wir könnten jetzt eine weitere Funktion schreiben, die die Daten direkt verwendet, d. h. wir nicht zuvor die Korrelationen berechnen müssten. Im 📦 ppcor-Paket existiert jedoch auch bereits die Funktion pcor.test(x, y, z), welche den Einfluss der Variablen z herauspartialisiert. Wir betrachten im Output vorerst nur den Schätzer (estimate)
aller Variablen einer Matrix respektive eines Dataframes berechnet:
Ferner lassen sich mit pcor() alle partiellen Korrelationen eines Dataframes berechnen. Wir betrachten entsprechend nur den Schätzer für \(r_{x_0,x_1}\):
part_korrel_output <- ppcor::pcor(df_1)
part_korrel_output$estimate| term | x0 | x1 | x2 |
|---|---|---|---|
| x0 | — | — | — |
| x1 | .68 | — | — |
| x2 | .16 | .45 | — |
- In der oberen Menu-Leiste Klick auf Analysieren
- im Dropdownmenu Korrelation ➡️ partiell… auswählen
- die beiden Variablen
x0undx1markieren und mit Klick auf ↪️ zu Variablen hinzufügen - analog die Variable
x2markieren und zu Kontrollvariablen hinzufügen - mit Klick auf 🆗 bestätigen oder besser auf Einfügen klicken und die Synatax ausführen
Alternativ kann direkt folgende Synatax verwendet werden:
PARTIAL CORR
/VARIABLES=x0 x1 BY x2
/SIGNIFICANCE=TWOTAIL
/MISSING=LISTWISE.Teilaufgabe c
Personen, die stärker sozial erwünschtes Verhalten zeigen, sind ebenso eher kontaktfreudig, da sie sich auch zwischenmenschlich sozial erwünscht verhalten. Für gewissenhafte Personen ist das nicht zwangsläufig der Fall, aber eben dann plausibel, wenn sie hoch auf sozialer Erwünschtheit scoren. Soziale Erwünschtheit könnte also als Mediator dienen (wobei auch andere [komplexere] Modelle denkbar sind):
:::
flowchart LR A[X0] --> B(X2) B --> C[X1] A --> C
x0= Gewissenhaftigkeit,x1= Kontaktfähigkeit,x2= soziale Erwünschtheit
Teilaufgabe d
Sollen Werte x0 von einer Variable x2 bereinigt werden, so kann diese über die Regressionsrechnung wie folgt geschehen: Die Werte von x0 (AV) werden durch x1 (UV) vorhergesagt. Jener Anteil, der vorhergesagt werden kann (aufgeklärte Varianz) kann als abhängig betrachtet werden. Der übrige Anteil an (unerklärter) Fehlervarianz (d.h. die Residuen) ist jedoch zwangsläufig unabhängig. Bei den bereinigten Werten handelt es sich also schlichtweg um die Regressionsresiduen:
Sofern die bereinigten Werte wirklich unabhängig sind, müssen sie mit x2 zu null korrelieren:
df_1 %>% mutate(id = row_number(), .before = x0) %>%
full_join(df_x0_star, by = "id") -> df_1_edit
df_1_edit %$% cor(x0_star, x2) %>% round(., 3)[1] 0Dasselbe gilt für die Variable x1, entsprechend ist auch das Vorgehen analog:
df_1_edit <- lm(x1 ~ x2, data = df_1) %>%
residuals() %>%
tidy() %>%
mutate(id = as.numeric(names), .before = x) %>%
rename(x1_star = x) %>%
select(-names) %>%
full_join(df_1_edit, by = "id")
df_1_edit %$% cor(x1_star, x2) %>% round(., 3)[1] 0Die Korrelationen der Residuen mit der Variable x3 sind in beiden Fällen wie zu erwarten null. Der erweiterte Dataframe sieht wie folgt aus:
Anmerkung: Die Residuen berechnen sich als \(x_0^* = x_0 - \hat{x}_0\) bzw. \(x_1^* = x_1 - \hat{x}_1\). Entsprechend kann die Berechnung in R auch erfolgen, indem von den jeweiligen x-Werten ihre vorhersagesagten Werte abgezogen werden:
df_1_predct<- lm(x0 ~ x2, data = df_1) %>%
predict() %>%
tidy() %>%
mutate(id = as.numeric(names), .before = x) %>%
rename(x0_predict = x) %>%
full_join(df_1_edit, by = "id") %>%
select(-names, -x1_star, -x1, x2) %>%
mutate(x0_star_new = x0 - x0_predict)Warning: 'tidy.numeric' ist veraltet.
Siehe help("Deprecated")[1] 0[1] 1- In der oberen Menu-Leiste Klick auf Analysieren
- im Dropdownmenu Regression ➡️ Linear… auswählen
- die Variable
x0markieren und mit Klick auf ↪️ zu Abhängige Variable hinzufügen - analog die Variable
x2markieren und zu Unabhängige Variable(n) hinzufügen - durch Klick auf Speichern öffnet sich ein weiteres Fenster, darin unter den abgegrenzten Bereichen Vorhergesagt Werte bzw. Residuen die Option ☑️ Nicht standardisiert anwählen und mit Klick auf Weiter bestätigen
- mit Klick auf 🆗 im vorherigen Fenster bestätigen oder besser auf Einfügen klicken und die Synatax ausführen.
Alternativ kann direkt folgende Synatax verwendet werden:
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT x0
/METHOD=ENTER x2
/SAVE PRED RESID.Im Datensatz erscheinen die beiden neuen Variablen PRE_1 und RES_1. Die Werte sind wie folgt zu interpretieren: es ergeben sich die beobachteten Werte x0, die vorhergesagten werden PRE_1 und die bereinigten Werte RES_1. Am Beispiel der zweiten Versuchsperson veranschaulicht bedeutet das: Bei VP2 wird ein Wert von \(x_{0_1} =5\) beobachtet, von \(x_{pred._1} = 5.29\) vorhergesagt, die Differenz zwischen tatsächlichem und vorhersagtem Wert ist \(x_{res_1}=0.29\). Wir könnten nun also eine neue Variable als Differenz beider Variablen berechnen:
COMPUTE x0_stern = x0-PRE_1.
EXECUTE.Wie wir aber berits gesehen haben, handelt es sich beim Ergebnis um die Residuen, entsprechend können wir diese direkt verwenden.
Dasselbe machen wir nun für die Varialbe x2, nachfolgend nur via Synatax dargestellt:
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT x1
/METHOD=ENTER x2
/SAVE PRED RESID.Egal welches Vorgehen gewählt wird, für die nächste Aufgabe benötigen wir die bereinigten Werte (Residuen), die wir als x0_stern bzw. x1_stern benennen.
Teilaufgabe e
Die Korrelation der von sozialer Erwünschtheit bereinigten Werte Gewissenhaftigkeit (x0_star) und Kontaktfähigkeit (x1_star) beträgt \(r_{01\cdot2}=.68\). Wir erhalten also dasselbe Ergebnis wie durch Nutzung der Formel in Teilaufgabe b.
- In der oberen Menu-Leiste Klick auf Analysieren
- im Dropdownmenu Korrelation ➡️ Bivariat auswählen
- die beiden Variablen
x0_sternundx1_sternmarkieren sowie via Drag and Drop oder via Klick auf ↪️ zu Variablen hinzufügen - im Abschnitt Korrelationskoeffizienten die Option ☑️ Pearson anwählen
- mit Klick auf 🆗 bestätigen oder besser auf Einfügen klicken und die Synatax ausführen
Alternativ kann die folgende Synatax verwendet werden:
CORRELATIONS
/VARIABLES=x0_stern x1_stern
/PRINT=TWOTAIL NOSIG FULL
/MISSING=PAIRWISE.Teilaufgabe f
Die partielle Korrelation bzw. deren zugehöriger t-Wert hat \(n-q-2\) Freiheitsgrade. Bei einer partiellen Korrelation erster Ordnung (\(q=1\)) und \(n=12\) Personen ergeben sich \(df=12-1-2=9\) Freiheitsgrade.
N <- nrow(df_1)
Q <- 1
deg_free <- N - Q - 2
deg_free[1] 9:::
Teilaufgabe g
Einsetzen in die Formel liefert:
t_emp <- r_part01 * sqrt(deg_free / (1-r_part01^2) ) Aus \[ t=.68\times\sqrt{\frac{12-1-2}{1-.68^2}} \] ergibt sich \(t_{emp}=\) 2.79
p_value <- pt(q = t_emp, df = deg_free, lower.tail = FALSE) * 2
p_value[1] 0.02106018Der zugehörige p-Wert ist \(p=\) 0.02
Wie wir oben bereits gesehen haben, erhalten wir alle Werte direkt mit der pcor.test()-Funktion:
Wir benennen das aktuelle Datenset um zu ROHDATEN
DATASET NAME ROHDATEN.Außerdem öffnen wir ein neues Dataset, in das wir die Variable n hardcoden, d.h. wir schreiben in das erste Feld (1,1) den Wert 12. Dieses Datenset benennen wir wie jenes zuvor um zu BERECHNUNGEN.
Im Syntax-Fenster können wir nun unter Aktives Dataset im Dropdown-Menu wählen, welches der beiden Datasets verwendet werden soll.
Warnung! In der Musterlösung wird die Korrelation \(r = .681\) aus dem Output der vorherigen Aufgabe übernommen hardgecoded (indirekt) in die Formel übertragen. Für wessen Nerven das zu viel ist, überspringt lieber folgenden Chunk:
COMPUTE r=0.681.
COMPUTE df=n-1-2.
COMPUTE t=r*sqrt(df/(1-r**2)).
COMPUTE pwert=2*(1-CDF.T(t, df)).
LIST.Anmerkung. Während das Es in mir sich nach dieser Lösung von der Uni exmatrikulieren (oder zumindest SPSS direkt wieder deinstallieren) wollte, strebte das Über-Ich die Suche nach einer besseren Lösung an. Unter div. Funktionen, die die SPSS Synatax bereithält, existiert jedoch keine, die zu cor() (siehe Lösung in R) vergleichbar wäre3. Mit CORRELATIONS ist der Output eine \(2\times2\) Matrix + weitere Dinge, die wir nie bestellt hatten. Daraus dann die Korrelation abzuschreiben, ist generell (und insbesondere bei Dezimalzahlen) die denkbar schlechteste Lösung. Das Ich in mir hat sich zu folgendem Kompromiss entschieden: SPSS schließen und es nie wieder zu öffnen. Es folgen daher nur noch die Lösungen für R.
Teilaufgabe h
Die Teststatistik berechnet sich nach folgender Formel:
\[ z = \sqrt{n-q-3}\times(Z-Z_0) \]
mit (klein) \(z\) als Teststatistik, die gegen die Normalverteilung getestet werden kann, \(Z\) als dem Fischer Z-Wert aus der beobachteten Korrelation und \(Z_0\) als jenem Z-Wert, der in der Null-Hypothese angenommen wird. Für die Berechnung muss also die Fishers Z-Transformation für die empirische und die theoretisch angenommene Korrelation durchgeführt werden:
\[Z=\frac{1}{2}\log\left({\frac{1+x}{1-x}}\right)\] mit \(x\) als Korrelation \(r\). Aufgelöst nach \(x\) bzw. \(r\) ergibt sich: \[ x = \frac{e^{2Z}-1}{e^{2Z}+1} \]
Für die empirisch beobachtete Korrelation errechnet sich folgender Z-Wert:
Denselben Z-Wert erhalten wir auch mittels der Funktion FisherZ() aus dem 📦 DescTools-Paket:
DescTools::FisherZ(r_part01)[1] 0.8309551Für den theoretisch angenommenen Wert ergibt sich also:
Der Fisher-Z-Wert ist von Vorteil, da er einer Normalverteilung folgt, \(z\sim\mathcal{N}(\mu,\,\sigma^{2})\). Entsprechend kann \(z\) gegen die Normalverteilung getestet werden:
Zwar ist \(p>.05\), lässt sich jedoch exakt berechnen als:
Somit kann \(\rho = 0.5\) als wahre Korrelation nicht verworfen werden.
Teilaufgabe i
Der Z-Wert wird aus vorheriger Aufgabe übernommen. Der Standardfehler berechnet sich wie folgt:
Die Konfidenzintervalle berechnen sich wie folgt:
\[ z - \sigma_z \times 1.96 \leq z_\rho \leq z + \sigma_z \times 1.96 \]
[1] 0.1380032[1] 1.523907Allerdings wollen wir nich das Konfidenzintervall für z, sondern für die Korrelation selbst. Die Transformation kann für die oben genannte Formel erfolgen: \[ x = \frac{e^{2Z}-1}{e^{2Z}+1} \]
Nachdem wir deren Anwendung gezeigt haben, können wir auch auch hier wieder die entsprechende inverse Funktion aus dem 📦 DescTools-Paket nutzen, nämlich FisherZInv():
r_OG <- DescTools::FisherZInv(Z_OG)
r_UG <- DescTools::FisherZInv(Z_UG)
r_OG; r_UG[1] 0.9093761[1] 0.1371337Voraussetzungsüberprüfung
Zwar bedüfen partielle Korrelationen keiner spezifischer Voraussetzungen, wohl aber die Signifikanztests.
Normalverteilungsannahme
In der Vorlesung wird vorgeschlagen sich Histogramme der einzelnen Variablen anzeigen zu lassen:
Code
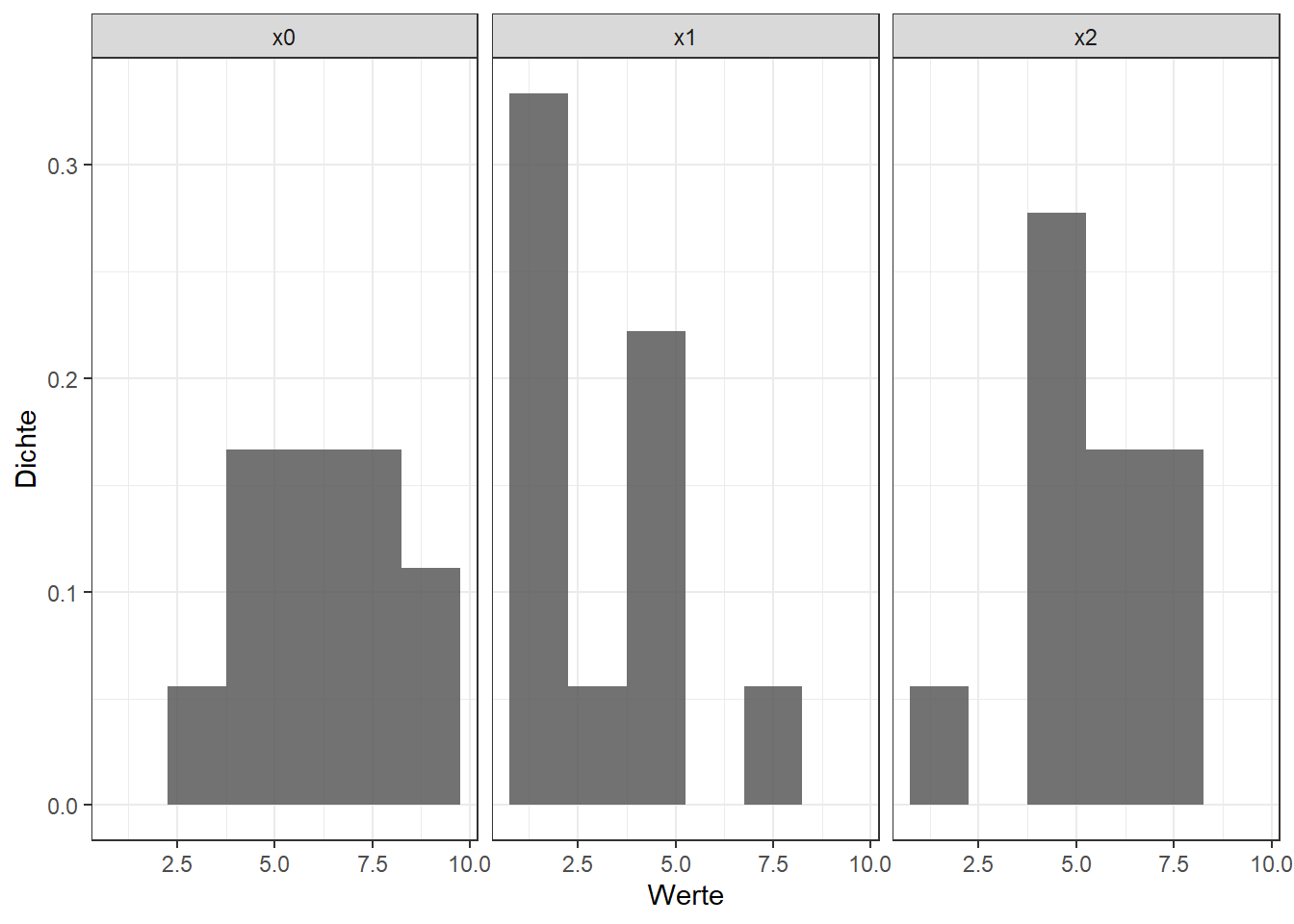
Diese Normalverteilungen könnten schöner kaum sein 🤦. Was die Güte angeht, so hat dieser Plot mehr Nähe zum Thematischen Apperzeptionstest als dass damit irgendeine Entscheidung getroffen werden könnte. Sofern man sich also für eine optische Überprüfung entscheidet, sind QQ-Plots m.E. nach die bessere Wahl, insbesondere wie hier bei kleinen Stichproben:
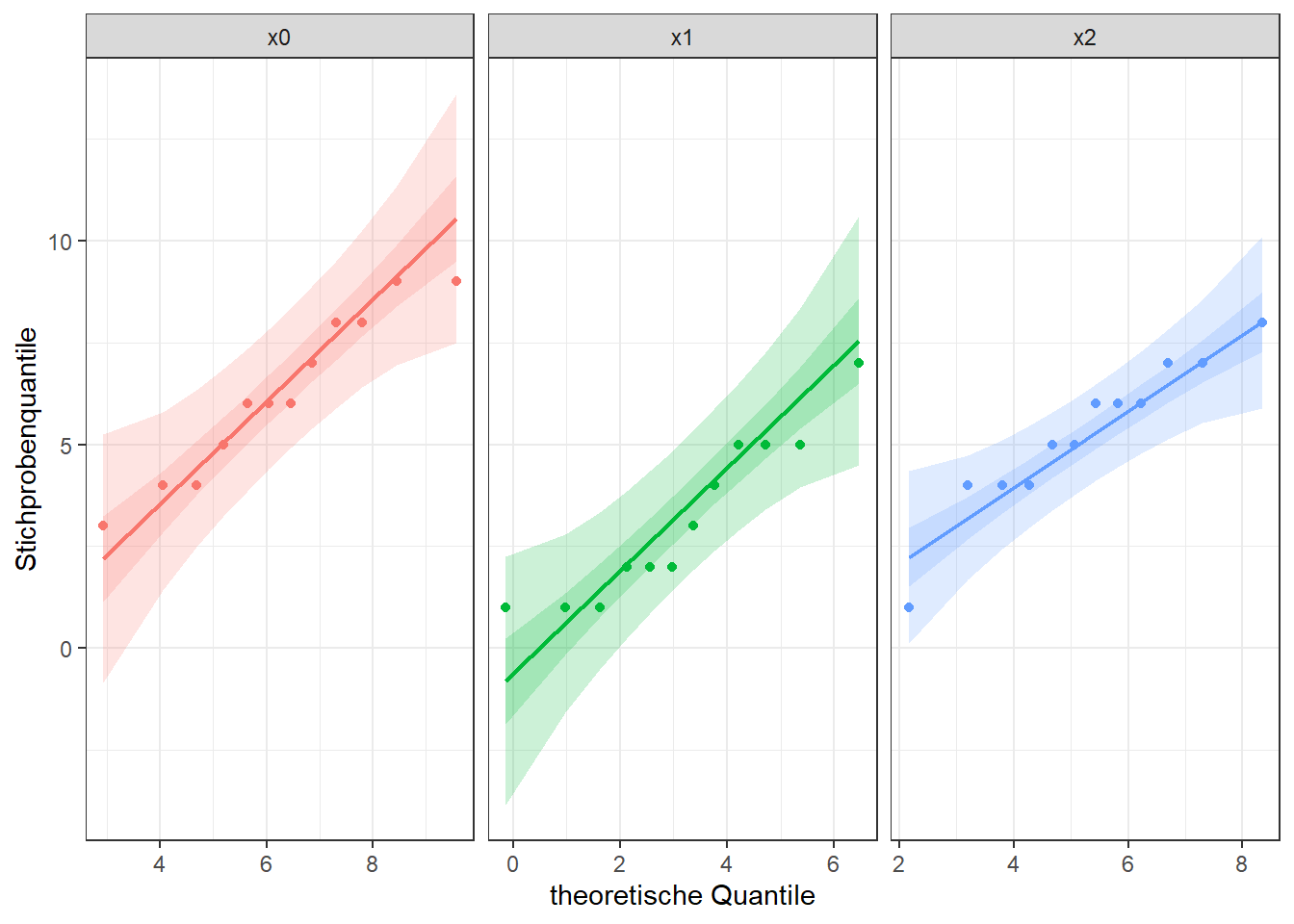
Dieser Plot schallert ja schon ganz anders! Die Werte liegen alle innerhalb der 95%-Konfidenzintervalle (darin dunkler dargestellt 50%-KIs).
Literaturverzeichnis
Bortz, J., & Schuster, C. (2010). Statistik für Human- und Sozialwissenschaftler (7. Aufl.). Springer. https://doi.org/10.1007/978-3-642-12770-0
Hildreth, C., & John, Y. L. (1960). Demand relations with autocorrelated disturbances. (Technical Bulletin, Bd. 276). Michigan State University.
Fußnoten
Pakete dienen nur zur Erstellung des Blogs und müssen nicht zwangsläufig geladen werden, sie sind vollständigkeitshalber aufgeführt↩︎
Nicht alle Pakete werden geladen, da diese teils vorhandene Funktionen blockieren, z. B. läd das 📦
ppcor- indirekt das 📦MASS-Paket, welches dieselect()-Funktion beansprucht, die jedoch 📦dplyrvorbehalten bleiben soll↩︎zumindst nicht in der zum Zeitpunkt des Blogs aktuellen Version 29 von IBM SPSS Statistics (2022).↩︎