Multiple lineare Regression
Wie es der Name vermuten lässt, kommt in der multiplen linearen Regression – im Vergleich zur einfachen Regression – mehr als nur ein Prädiktor zum Einsatz. Damit knüpft die multiple Regression inhaltlich fließend an die partielle Korrelation (vergangener Post) an. Wie wir dort gesehen hatten, können Variablen aufeinander einwirken, oder anders gesagt klären zwei Prädiktoren \(x_1\) und \(x_2\) meist nicht exklusiv Varianz des Kriteriums \(y\) auf, sondern es gibt eine Überschneidung der aufgeklärten Varianzanteile. In einem Modell lm(y ~ x1 + x2). Könnten wir nun zur Berechnung der Steigungskoefizienten die partielle Korrelation heranziehen bzw. die Werte wie gehabt bereinigen. Das hätte aber zur Folge, dass wenn der Einfluss von \(x_2\) sowohl auf das Kriterium \(y\) als auch auf den anderen Prädiktor \(x_1\) bereinigt würde, \(x_2\) selbst zu \(\rho = 0\) mit dem Kriterium korrelieren-, d.h. also gar keine Varianz mehr aufklären würde. Was wir also stattdessen benötigen ist eine nur teils bereinigte Korrelation: während \(x_1\) von \(x_2\) bereinigt wird, soll das Kriterium unberührt bleiben und vice versa für den umgekehrten Einfluss von \(x_1\) auf \(x_2\). Dies geschieht mit der semipartiellen Korrelation.
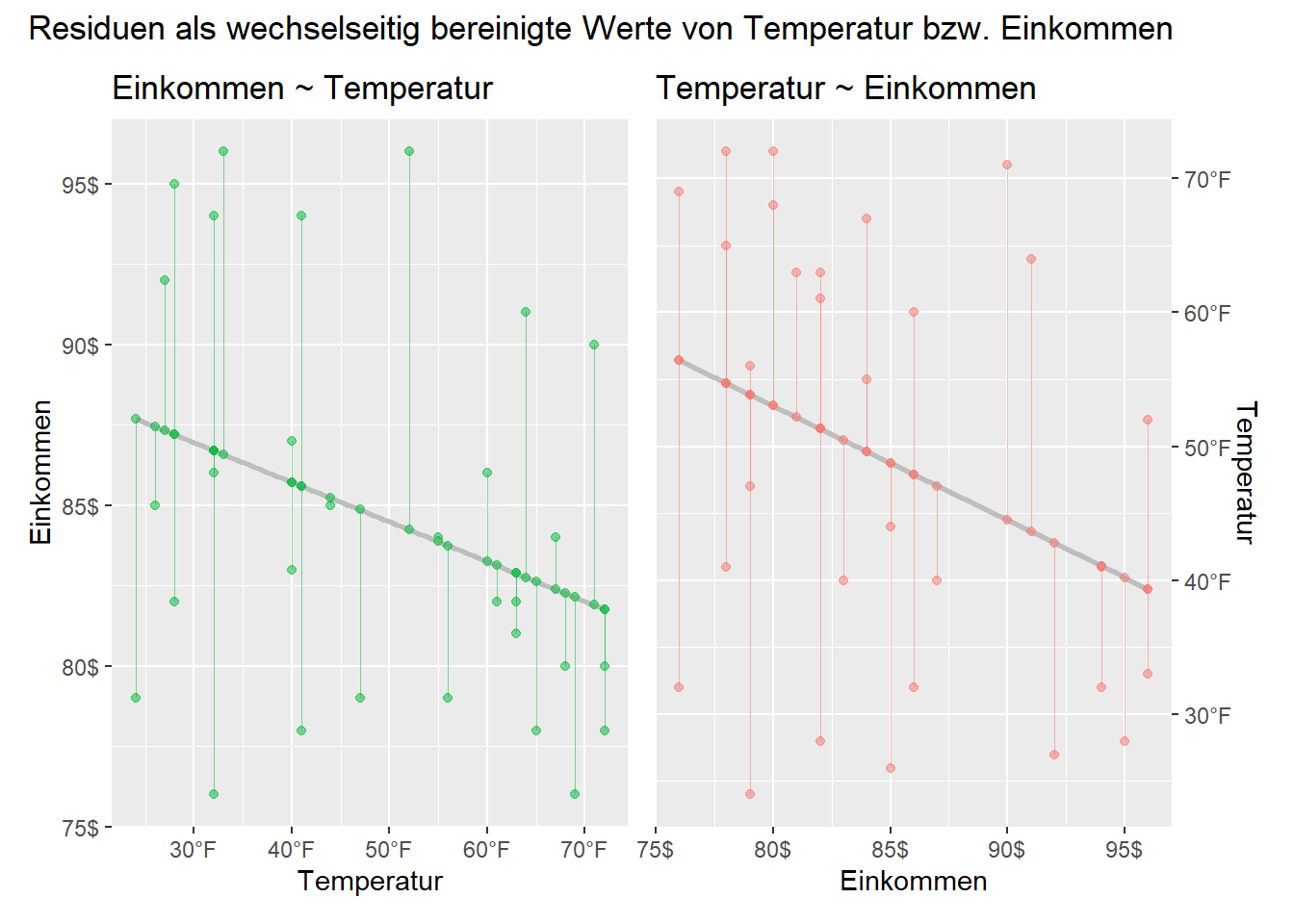
Zur Veranschaulichung nutzen wir erneut das Eis-Beispiel (Hildreth & John, 1960) des vergangenen Posts. Wieder können wir uns die bereinigten Werte grafisch veranschaulichen:
Wir können die in der Abbildung veranschaulichten Residuen (bereinigte Werte) in einem ersten Schritt wie folgt berechen:
Anschließend sagen wir mit den bereinigten Werten das belassene Kriterium hervor. Durch die Vorhersage mittels \(x_1^*\) erhalten wir entsprechend \(b_1\) und ebenso \(b_2\) durch \(x_2^*\):
(Intercept) temp_star
0.359433333 0.003543306 (Intercept) income_star
0.359433333 0.003530167 Die ermittelten Regressionskoefizienten sind identisch mit jenen, die erhalten, wenn wir mit beiden Prädiktoren in einem gemeinsamen Modell den Eiskonsum vorhersagen:
Call:
lm(formula = cons ~ temp + income, data = df_ice)
Residuals:
Min 1Q Median 3Q Max
-0.065420 -0.022458 0.004026 0.015987 0.091905
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.113195 0.108280 -1.045 0.30511
temp 0.003543 0.000445 7.963 1.47e-08 ***
income 0.003530 0.001170 3.017 0.00551 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.03722 on 27 degrees of freedom
Multiple R-squared: 0.7021, Adjusted R-squared: 0.68
F-statistic: 31.81 on 2 and 27 DF, p-value: 7.957e-08Hinzufügen eines dritten Prädiktors führt dazu, dass aus den Variablen nun der Einfluss von zwei Variablen herauspartialisiert wird. Z. B. hatten wir für den Preis angenommen, dass dieser zwar weitestgehend stabil ist. Wollen wir für dessen Schwankungen aber denoch kontrollieren, können wir ihn aus weiteren Prädiktor hinzufügen (selbst wenn sich für ihn kein signifikanter Beitrag zur Vorgesage zeigen lässt):
Call:
lm(formula = cons ~ temp + income + price, data = df_ice)
Residuals:
Min 1Q Median 3Q Max
-0.065302 -0.011873 0.002737 0.015953 0.078986
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.1973151 0.2702162 0.730 0.47179
temp 0.0034584 0.0004455 7.762 3.1e-08 ***
income 0.0033078 0.0011714 2.824 0.00899 **
price -1.0444140 0.8343573 -1.252 0.22180
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.03683 on 26 degrees of freedom
Multiple R-squared: 0.719, Adjusted R-squared: 0.6866
F-statistic: 22.17 on 3 and 26 DF, p-value: 2.451e-07Pakete
Übungsaufgaben
Daten einlesen
df_2 <- read_sav(here("data", "mult", "daten.sav")) %>%
zap_formats() %>%
tibble()
df_2 %>% gt_preview(top_n = 3) %>%
tab_stubhead(label = "Region") %>%
tab_spanner(label = "y", columns = c(Y)) %>%
tab_spanner(label = "x1", columns = c(X1)) %>%
tab_spanner(label = "x2", columns = c(X2)) %>%
cols_align(align = "center", columns = everything()) %>%
cols_label(Y = md("Verkauf"),
X1 = md("Preis"), # or: md("**Preis**"),
X2 = md("Werbung"))| Region | y | x1 | x2 |
|---|---|---|---|
| Verkauf | Preis | Werbung | |
| 1 | 2417 | 7.20 | 850 |
| 2 | 2024 | 7.50 | 900 |
| 3 | 1933 | 6.99 | 700 |
| 4..9 | |||
| 10 | 928 | 6.50 | 115 |
Visualisierung
Code
df_2 %>% ggplot(aes(x = X1, y = Y, color = X2)) +
# geom_point() +
geom_jitter(width = 0.15, height = 0.15) +
geom_smooth(method = "lm", formula = 'y ~ x', se = FALSE) +
labs(x = bquote('Preis '(X[1])),
y = bquote('Verkaufszahl '(Y)),
# title = "Gewissenhaftigkeit in Relation zu Kontaktfähigkeit",
color = "soziale Erwünschtheit") +
theme_bw() +
scale_x_continuous(labels = scales::label_dollar(prefix = "€")) +
scale_colour_viridis_c(option = 'magma',
name = quote('Werbung '(X[2])))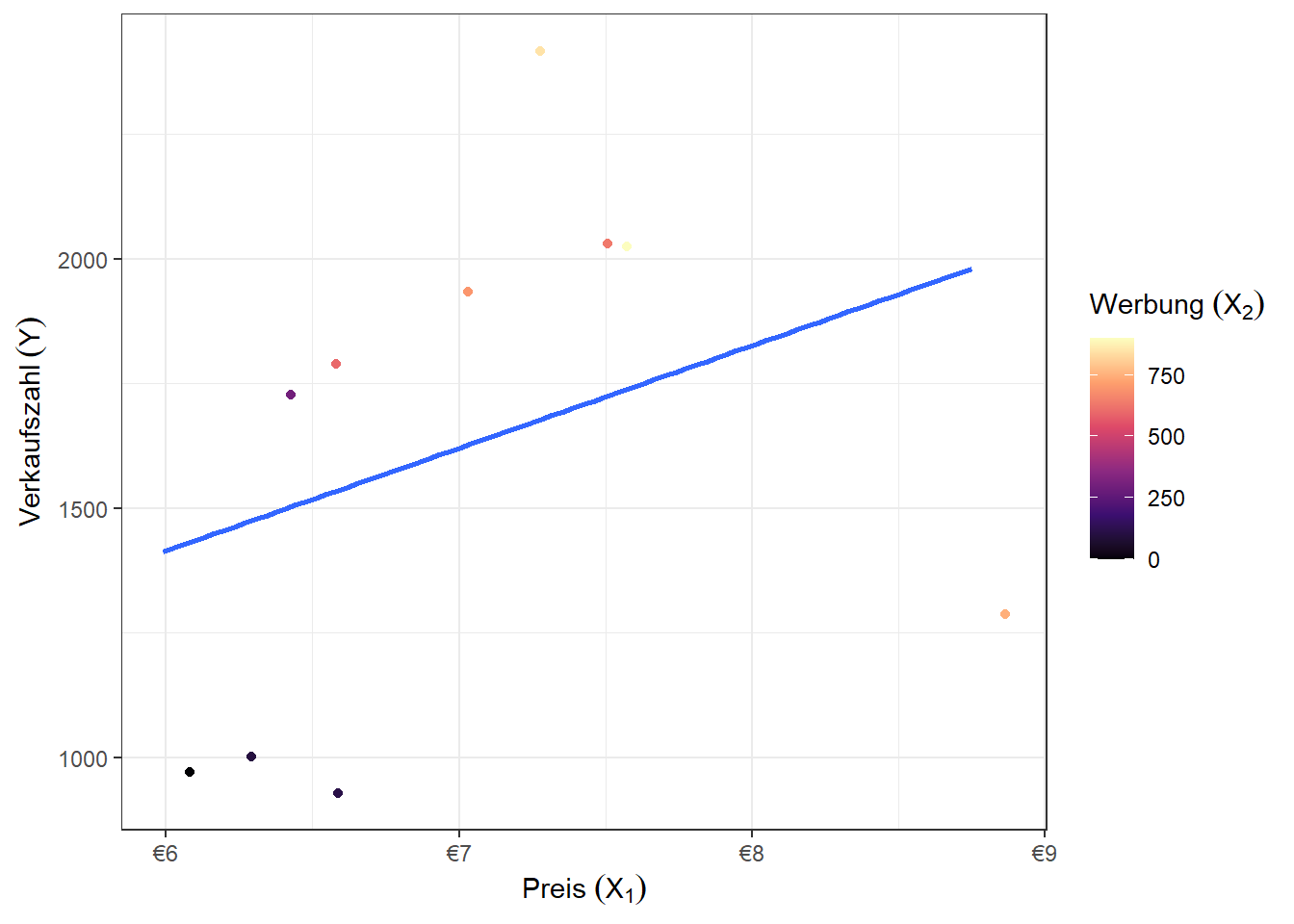
Teilaufgabe a
Die Korrelationen lassen sich in R als Korrelationsmatrix via cor() bestimmen (oder wie hier im Output under the hood mit correlate() und shave() aus dem Paket corrr):
cor(df_2)| term | Y | X1 | X2 |
|---|---|---|---|
| Y | — | — | — |
| X1 | .32 | — | — |
| X2 | .82 | .74 | — |
Teilaufgabe b
Standardisierte Verkaufszahlen lassen sich formal mit folgender Regressionsgleichung vorhersagen: \[
\operatorname{Y} = \beta_{0} + \beta_{1}(\operatorname{Preis}) + \beta_{2}(\operatorname{Werbung}) + \epsilon
\] bzw. \[
\operatorname{\hat{y}} = \beta_{0} + \beta_{1}(\operatorname{Preis}) + \beta_{2}(\operatorname{Werbung})
\] In R erfolgt die Berechnung analog via lm()-Funktion. Für die standardisierten Gewichte im selben Output nutzen wir die Funktion lm.beta aus dem gleichnamigen Paket:
| term | estimate | std_estimate | std.error | statistic | p.value |
|---|---|---|---|---|---|
| (Intercept) | 3462.64 | 816.39 | 4.24 | <.0001 | |
| X1 | -411.75 | -0.64 | 133.18 | -3.09 | .02 |
| X2 | 2.04 | 1.30 | 0.33 | 6.25 | <.0001 |
Teilaufgabe c
df_2 %>% summarise_each(funs(mean, sd))| Variable | M | SD |
|---|---|---|
| X1 | 6.95 | 0.82 |
| X2 | 495.00 | 335.19 |
| Y | 1610.80 | 526.83 |
Teilaufgabe d
Vgl. Teilaufgabe b
\[ \operatorname{Y} = b_{0} + b_{1}(\operatorname{Preis}) + b_{2}(\operatorname{Werbung}) + \epsilon \] bzw.
\[ \operatorname{\hat{y}} = b_{0} + b_{1}(\operatorname{Preis}) + b_{2}(\operatorname{Werbung}) \]
summary(mdl_1)| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 3462.64 | 816.39 | 4.24 | <.0001 |
| X1 | -411.75 | 133.18 | -3.09 | .02 |
| X2 | 2.04 | 0.33 | 6.25 | <.0001 |
Teilaufgabe e
Hier soll nun die Regressionsgleichung zunächst genutzt werden, um mit den geschätzen Gewichten eine Vorhersage für Y zu treffen. Dafür müssen zunächst die Gewichte \(b_0\), \(b_1\) und \(b_2\) berechnet werden. Dafür werden für ein standardisiertes Modell folgende Formeln für \(\beta_i\) genutzt:
\[\beta_1 = \frac{r_{y1}-r_{y2}*r_{12}}{1-r_{12}^2}\] \[\beta_2 = \frac{r_{y1}-r_{y2}*r_{12}}{1-r_{12}^2}\]
\[b_1 = \beta_1 * \frac{s_y}{s_1}\] \[b_2 = \beta_2 * \frac{s_y}{s_2}\]
\[b_0 = \bar{y} - b_1\bar{x}_1 - b_2\bar{x}_2\]
In den vorangegangenen Aufgaben wurden die Mittelwerte, Standardabweichungen und Korrelationen bereits berechnet (vgl. Teilaufgaben a, c). In R ist man mit folgendem Ansatz aber deutlich schneller (sofern man kein Base R nutzt):
df_2 %>% summarise(x_1 = 6.9530,
x_2 = 495,
r_y1 = cor(X1, Y),
r_y2 = cor(X2, Y),
r_12 = cor(X1, X2),
s_y = sd(Y),
s_1 = sd(X1),
s_2 = sd(X2),
B_1 = (r_y1-r_y2*r_12)/(1-r_12^2),
B_2 = (r_y2-r_y1*r_12)/(1-r_12^2),
b_1 = B_1 * (s_y/s_1),
b_2 = B_2 * (s_y/s_2),
b_0 = mean(Y) - b_1*mean(X1) - b_2*mean(X2)) -> df_estWir setzen die Parameter und vorgegebenen Werte in die Regressionsgleichung (vgl. Teilaufgabe d):
[1] 1611Dieses Ergebnis können wir mit R sehr leicht überprüfen:
df_new <- tibble(X1 = 6.9530, X2 = 495)
sales_pred <- predict(mdl_1, newdata = df_new) %>% round()
sales_pred 1
1611 Bei einem Preis von 6.95€ und einer Ausgabe 495€ erwarten wir eine Anzahl von rund 1611 verkauften Produkten.
Teilaufgaben f, g
| Term | b | beta | SE | Statistic | p |
|---|---|---|---|---|---|
| (Intercept) | 3462.64 | 816.39 | 4.24 | <.0001 | |
| X1 | -411.75 | -0.64 | 133.18 | -3.09 | .02 |
| X2 | 2.04 | 1.30 | 0.33 | 6.25 | <.0001 |
unstandardisierte Gewichte
Bei konstant gehaltener Werbung werden bei Preiserhöhung um einen Euro rund 411 Produkte weniger verkauft. Umgekehrt werden bei konstant gehaltenem Preis und bei einer Mehrausgabe von einem Euro für Werbung 2 Produkte mehr verkauft.
standardisierte (Beta) Gewichte
Bei Erhöhung des Preises um eine Standardabweichung sinkt die Verkaufszahl um 0.64 Standardabweichungen, sofern die Variable Werbung dabei konstant gehalten wird. Umgekehrt werden bei Erhöhung der Werbeausgaben um eine Standardabweichung die Verkaufszahlen um 1.3 Standardabweichungen gesteigert, bei konstant gehaltenem Verkaufspreis.
Teilaufgabe h
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 1610.80 | 159.44 | 10.10 | <.0001 |
| X1_star | -411.75 | 304.63 | -1.35 | .21 |
Für beide Varianten ergibt sich ein \(b_1 = -411.75\).
Teilaufgabe i
Teilaufgabe j
Rohwerte:
Berechnung:
| y_pred | X1 | X2 |
|---|---|---|
| 2013.41 | 6 | 500 |
| 2217.67 | 6 | 600 |
| 2421.93 | 6 | 700 |
| 1601.66 | 7 | 500 |
| 1805.92 | 7 | 600 |
| 2010.18 | 7 | 700 |
Voraussetzungen
Literaturverzeichnis
Hildreth, C., & John, Y. L. (1960). Demand relations with autocorrelated disturbances. (Technical Bulletin, Bd. 276). Michigan State University.