Pakete
Übungsaufgaben
Aufgabe 1
Daten einlesen
df_3 <- read_sav(here("data", "mult2", "daten.sav")) %>%
zap_formats() %>%
janitor::clean_names() %>%
tibble() %>%
mutate(Person = 1:10)
df_3 %>% select(-Person) %>%
gt_preview(top_n = 3) %>%
tab_stubhead(label = "Person") %>%
cols_align(align = "center", columns = everything())| Person | y | x1 | x2 | x3 |
|---|---|---|---|---|
| 1 | 4 | 3 | 8 | 1 |
| 2 | 5 | 4 | 8 | 3 |
| 3 | 7 | 3 | 5 | 5 |
| 4..9 | ||||
| 10 | 9 | 6 | 2 | 3 |
Visualisierung
Code
df_temp %>% pivot_longer(names_to = "var", values_to = "x", -c(Person, y)) %>%
mutate(Prediktor = case_when(var == "x1" ~ paste(var, "Sozialkompetenz", sep = ": "),
var == "x2" ~ paste(var, "Neurotizismus", sep = ": "),
var == "x3" ~ paste(var, "Gewissenhaftigkeit", sep = ": "))) %>%
ggplot(aes(x = x, y = y)) +
geom_jitter(width = 0.15, height = 0.15) +
stat_smooth(geom = "smooth", method = "lm",
formula = 'y ~ x', se = FALSE, fullrange = TRUE) +
facet_grid(~Prediktor) +
labs(x = bquote('Persönlichkeitsskala '(X[i])),
y = bquote('Arbeitsleistung '(Y)) ) +
theme_bw() 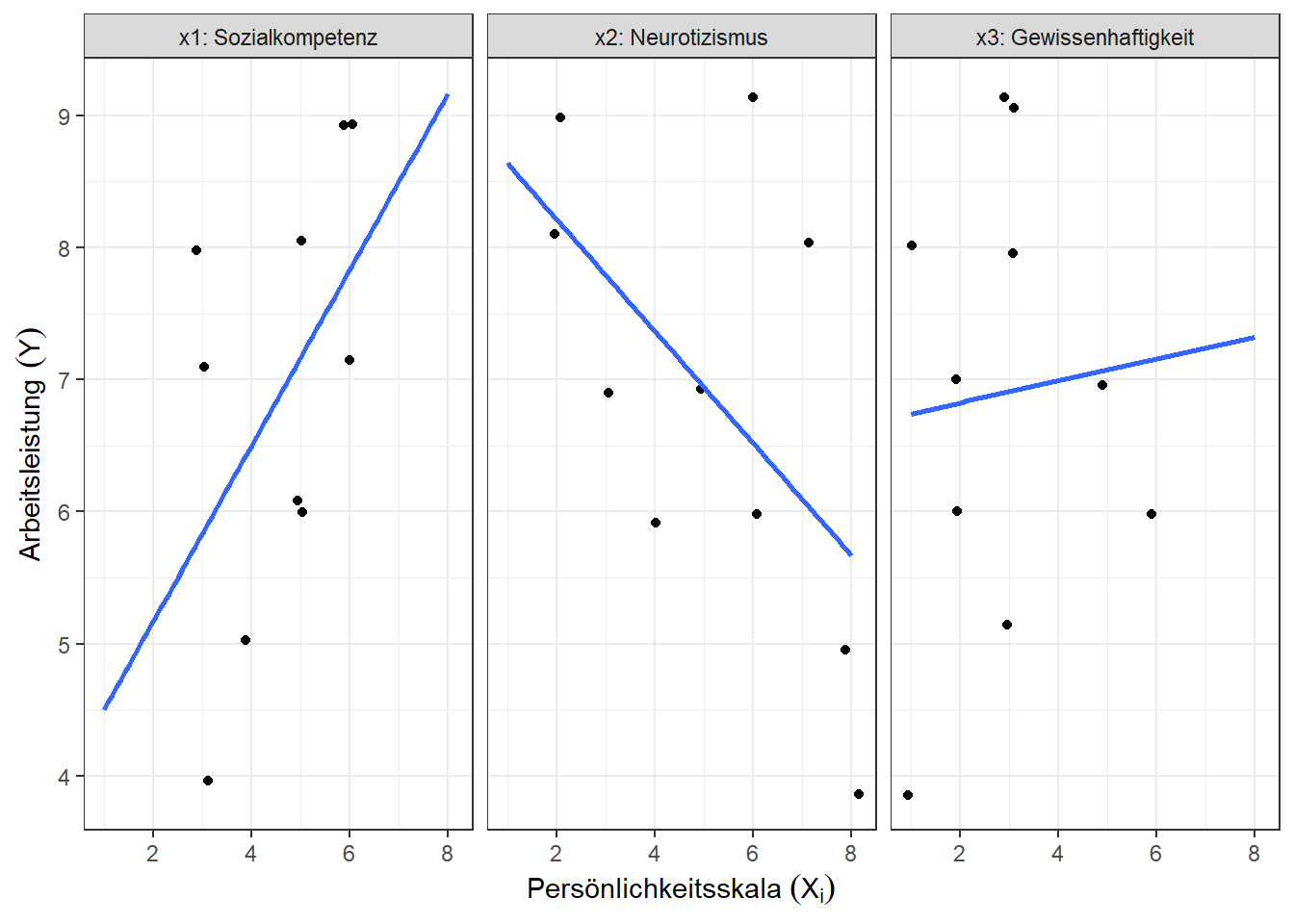
Teilaufgabe a
\[ \operatorname{Y} = b_{0} + b_{1}x_1 + b_{2}x_2 + b_{3}x_3 + \epsilon \]
mdl_1 <- lm(y ~ x1 + x2 + x3, data = df_3)- In der oberen Menu-Leiste Klick auf Analysieren
- im Dropdownmenu unter dem Punkt Regression ➡️ Linear… auswählen
- die AV
Leistung [Y]markieren und mit Klick auf ↪️ zu Abhängige Variable hinzufügen - die drei UVs
Soziale Kompetenz [X1],Neurotizismus [X2]undGewissenhaftigkeit [X3]markieren und mit Klick auf ↪️ zu Unabhängige Variable(n) hinzufügen - Optional: nach Klick auf den Button Statistiken… im Pop-up Fenster die Option ☑️ Deskriptive Statistik sowie ☑️ Konfidenzintervalle anwählen und mit Klick auf Weiter bestätigen
- mit Klick auf 🆗 im vorherigen Fenster die Analyse ausführen oder besser nach Klick auf Einfügen im Syntax-Fenster ausführen.
Im Output werden die unten dargestellten Tabellen ausgegeben.
Alternativ folgende Syntax eingeben
REGRESSION
/DESCRIPTIVES MEAN STDDEV CORR SIG N
/MISSING LISTWISE
/STATISTICS COEFF OUTS CI(95) R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT Y
/METHOD=ENTER X1 X2 X3.sum_obj <- summary.lm(mdl_1)
sqrt(sum_obj$r.squared)[1] 0.608212sum_obj
Call:
lm(formula = y ~ x1 + x2 + x3, data = df_3)
Residuals:
Min 1Q Median 3Q Max
-1.5060 -0.9447 -0.3618 0.6597 2.1757
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.156029 3.869435 1.849 0.114
x1 0.300670 0.555995 0.541 0.608
x2 -0.318334 0.307090 -1.037 0.340
x3 -0.005382 0.341653 -0.016 0.988
Residual standard error: 1.617 on 6 degrees of freedom
Multiple R-squared: 0.3699, Adjusted R-squared: 0.05488
F-statistic: 1.174 on 3 and 6 DF, p-value: 0.3949Das Kriterium Arbeitsleistung (\(y\)) korreliert mit den durch die Prädiktoren vorhergesagten Werten (\(\hat{y}\)) zu \(R=.61\).1
Mit \(R^2=.37\) wird mehr als ein Drittel der Varianz durch das Modell aufgeklärt (36.99%). Der korrigierte Determinationskoeffizient \(R_{adj.}^2=.05\) fällt deutlich geringer aus (5.49%), was auf die geringe Stichprobengröße von nur \(n=10\) Personen zurückgeführt werden kann.
Die Hypothese \(H_0: ϱ^2 = 0\) bzw. \(H_0: \beta_1 = \beta_2 = \beta_3 = 0\) kann mit \(F(3,6)=1.17\), \(p>.05\) nicht verworfen werden, d.h. es kann für keinen der Prädiktoren gezeigt werden, dass er einen signifikanten Anteil an Varianz aufklärt (\(p=0.39\)).
Die einzelnen (mittleren) Quardratsummen können in R mittels anova(mdl_1) ausgegeben werden:
anova(mdl_1) # %>% tidy()Analysis of Variance Table
Response: y
Df Sum Sq Mean Sq F value Pr(>F)
x1 1 6.4000 6.4000 2.4476 0.1687
x2 1 2.8104 2.8104 1.0748 0.3398
x3 1 0.0006 0.0006 0.0002 0.9879
Residuals 6 15.6889 2.6148 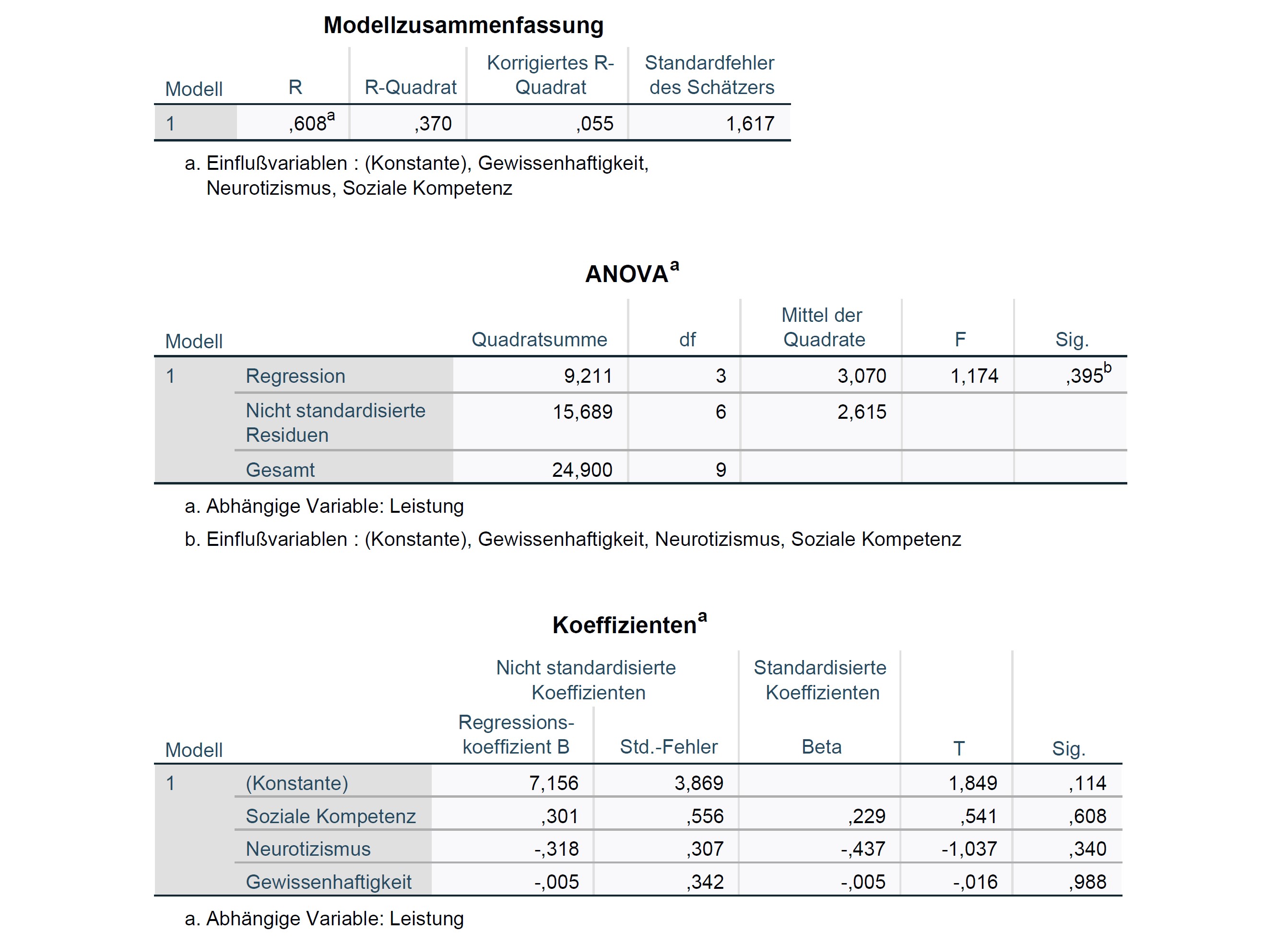
Die Interpretation der Werte erfolgt analog zu jener via R.
Teilaufgabe b
Standardschätzfehler und dessen Freiheitsgrade sind im summary.lm-Objekt (vgl. str(sum_obj)):
s_e <- sum_obj$sigma
deg_free <- sum_obj$df[2] # or: mdl_1$df.residual
s_e; deg_free[1] 1.617042[1] 6Standardschätzfehler beträgt \(\hat{\sigma}=\) 1.62 und hat \(df=6\) Freiheitsgrade.
Für mehr siehe: ?summary.lm()
Teilaufgabe c
Die Standardabweichung der AV beträgt \(s_y=\) 1.66. Im Vergleich zu deren Streuung sollte der Fehler entsprechend kleiner ausfallen, sofern die Prädiktoren eine gute Vorhersagt liefern. Jedoch ist \(\hat{\sigma}=\) 1.62, sprich ähnlich groß, was nicht für das Modell spricht.
Teilaufgabe d
sum_obj %>% coefficients()sum_obj %>% coefficients() %>%
data.frame() %>%
rownames_to_column(var = "Quelle") %>%
mutate_if(is.numeric, ~round(., 2)) %>% # str()
rename(b = "Estimate", SE = "Std..Error", t = "t.value", p = "Pr...t..") %>%
rstatix::p_format(digits = 2, leading.zero = FALSE) %>%
kbl() %>%
kable_paper("hover", full_width = F)Merke: Die partielle Steigung \(b_j\) gibt die erwartete Veränderung des Kriteriums \(y\) an, die einer Erhöhung des j-ten Prädiktors um eine Einheit entspricht, wenn die anderen \(k-1\) Prädiktoren konstant sind.
Gegeben die Skalen zur Messung der Prädiktoren sind vergleichbar, dann können deren unstandardisierte Gewichte \(b_i\) wie folgt interpretiert werden:
- \(b_1 = 0.30\): Werden die Werte für Neurotizismus (\(x_2\)) und Gewissenhaftigkeit (\(x_3\)) konstant gehalten, so geht eine Steigerung um einen Punkt auf der Skala soziale kompetenz (\(x_1\)) mit einer Steigerung der Arbeitsleistung (\(y\)) um 0.3 Einheiten einher.
- \(b_2 = -0.32\): Werden die Werte für soziale kompetenz (\(x_1\)) und Gewissenhaftigkeit (\(x_3\)) konstant gehalten, so geht eine Steigerung um einen Punkt auf der Skala Neurotizismus (\(x_1\)) mit einer Verringerung der Arbeitsleistung (\(y\)) um -0.32 Einheiten einher.
- \(b_3 = -0.01\): Werden die Werte für soziale kompetenz (\(x_1\)) und Neurotizismus (\(x_2\)) konstant gehalten, so geht eine Steigerung um einen Punkt auf der Skala Gewissenhaftigkeit (\(x_3\)) mit einer Steigerung der Arbeitsleistung (\(y\)) um -0.01 Einheiten einher.
Dabei ist keine diese Veränderungen signifikant (alle Werte \(p > .05\)).
Aufgabe 2
Teilaufgabe a
Wir berechnen zunächst die bereinigte x3 Variable:
lm(x1 ~ x2 + x3, data = df_3) %>% residuals() %>%
data.frame(Person = 1:10, x1_star = .) %>%
right_join(df_3, by = "Person") %>%
relocate(x1_star, .after = x3) -> df_3_edit\(b_1\) kann nun über folgende Formel berechnet werden:
\[ b_j = sr_j \frac{s_y}{s_j^*} \]
Wir berechnen also die fehlenden Variablen
- \(sr_j\): Korrelation von Arbeitsleistung mit der bereinigten Variablen
- \(s_y\): Standardabweichung der AV Arbeitsleistung
- \(s_j^*\): Standardabweichung der bereinigten Variablen \(x_1^*\)
und setzen diese in die Formel ein:
- In der oberen Menu-Leiste Klick auf Analysieren
- im Dropdownmenu unter dem Punkt Regression ➡️ Linear… auswählen
- die AV
Soziale Kompetenz [X1]markieren und mit Klick auf ↪️ zu Abhängige Variable hinzufügen - die beiden verbleibenden UVs
Neurotizismus [X2]undGewissenhaftigkeit [X3]markieren und mit Klick auf ↪️ zu Unabhängige Variable(n) hinzufügen - Nach Klick auf den Button Speichern… im Pop-up Fenster in der Rubrik Residuen die Option ☑️ Nicht standardisiert anwählen und mit Klick auf Weiter bestätigen
- mit Klick auf 🆗 im vorherigen Fenster die Analyse ausführen
Im Datensatz ist die neue Variable RES_1 hinzugefügt worden. Umbenennung zu X1_star.
Teilaufgabe b
Der Standardfehler \(s_{b_1}\) wird mit folgender Formel berechnet
\[ s_{b_j} =\frac{s_e}{\sqrt{QS_j^*}} \]
\[ s_j^* = \sqrt{\frac{QS_j^*}{n-1}} \]
Umstellung nach \(\sqrt{QS_j^*}\) liefert:
\[\sqrt{QS_j^*} = s_j^* \times \sqrt{n-1}\]
Teilaufgabe c
Multiplikation von \(b_1\) mit der Standardabweichung von \(x_1\) (\(s_{x_1}\)) geteilt durch die Standardabweichung von \(y\) (\(s_y\)):
\[ \beta_j = b_j \frac{s_{x_j}}{s_y} \]
df_3_edit %>% summarise(sr1 = cor(y, x1_star),
sy = sd(y),
s1_star = sd(x1_star),
b1 = sr1 * (sy/s1_star),
#' Teil b: s_b_1
N = nrow(df_3),
sqrt_QS1_star = s1_star * sqrt(N-1),
QS1_star = sqrt_QS1_star^2,
sb1 = s_e / sqrt_QS1_star,
#' Teil c: Beta 1
s1 = sd(x1),
beta1 = b1 * (s1 / sy)) -> df_3_stat
df_3_stat %>% pull(beta1) %>% round(3)[1] 0.229Teilaufgabe d
Der t-Wert ergibt sich durch Teilen des Steigungskoeffizienten durch den Standardfehler: \[ t=\frac{b_j}{s_{b_j}} \]
df_3_edit %>% summarise(sr1 = cor(y, x1_star),
sy = sd(y),
s1_star = sd(x1_star),
b1 = sr1 * (sy/s1_star),
#' Teil b: s_b_1
N = nrow(df_3),
sqrt_QS1_star = s1_star * sqrt(N-1),
QS1_star = sqrt_QS1_star^2,
sb1 = s_e / sqrt_QS1_star,
#' Teil c: Beta 1
s1 = sd(x1),
beta1 = b1 * (s1 / sy),
#' Teil d: t-Wert
t_val = b1 / sb1) -> df_3_stat
df_3_stat %>% pull(t_val) %>% round(3)[1] 0.541Teilaufgabe e
df_3_edit %>% summarise(sr1 = cor(y, x1_star),
sy = sd(y),
s1_star = sd(x1_star),
b1 = sr1 * (sy/s1_star),
#' Teil b: s_b_1
N = nrow(df_3),
sqrt_QS1_star = s1_star * sqrt(N-1),
QS1_star = sqrt_QS1_star^2,
sb1 = s_e / sqrt_QS1_star,
#' Teil c: Beta 1
s1 = sd(x1),
beta1 = b1 * (s1 / sy),
#' Teil d: t-Wert
t_val = b1 / sb1,
#' Teil e: p-Wert
p_val = pt(t_val, df = N-3-1, lower.tail = FALSE)*2) -> df_3_stat
df_3_stat %>% pull(p_val) %>% round(3)[1] 0.608Teilaufgabe f, g
\[ b_1 - t_{krit} \times s_{b_1} \leq \beta_1 \leq b_1 + t_{krit} \times s_{b_1} \]
Formel:
\[ KI_{UG} = b_1 - t_{krit} \times s_{b_1} KI_{OG} = b_1 + t_{krit} \times s_{b_1} \]
df_3_edit %>% summarise(sr1 = cor(y, x1_star),
sy = sd(y),
s1_star = sd(x1_star),
b1 = sr1 * (sy/s1_star),
#' Teil b: s_b_1
N = nrow(df_3),
sqrt_QS1_star = s1_star * sqrt(N-1),
QS1_star = sqrt_QS1_star^2,
sb1 = s_e / sqrt_QS1_star,
#' Teil c: Beta 1
s1 = sd(x1),
beta1 = b1 * (s1 / sy),
#' Teil d: t-Wert
t_val = b1 / sb1,
#' Teil e: p-Wert
p_val = pt(t_val, df = N-3-1, lower.tail = FALSE)*2,
#' Teil f, g: KI UG, OG
t_krit = qt(p = 0.975, df = deg_free),
KI_UG = b1 - t_krit * sb1,
KI_OG = b1 + t_krit * sb1) -> df_3_stat
df_3_stat %>% select(starts_with("KI")) %>% round(3) KI_UG KI_OG
1 -1.06 1.661Aufgabe 3
Teilaufgabe a
Korrelationen 0ter Ordnung
df_3 %>% select(starts_with(c("x", "y"))) %>%
cor() %>%
data.frame() %>%
rownames_to_column(var = "var") %>%
filter(var == "y") %>%
select(starts_with("x")) %>%
mutate(Korrelation = "pearson", .before = "x1") -> df_cor_1Partielle Korrelationen
df_3 %>% select(starts_with(c("x", "y"))) %>%
ppcor::pcor() %$% estimate %>%
data.frame() %>%
rownames_to_column(var = "var") %>%
filter(var == "y") %>%
select(starts_with("x")) %>%
mutate(Korrelation = "partiel", .before = "x1") -> df_cor_2Teilkorrelationen
df_3 %>% select(starts_with(c("x", "y"))) %>%
ppcor::spcor() %$% estimate %>%
data.frame() %>%
rownames_to_column(var = "var") %>%
filter(var == "y") %>%
select(starts_with("x")) %>%
mutate(Korrelation = "semipartiell", .before = "x1") -> df_cor_3Teilaufgabe b
\[Tol_j = 1-R^2 \Longleftrightarrow Tol_j = \frac{QS_j^*}{QS_j}\] Der VIF ergibt sich als Kehrwert der Toleranz: \[VIF_j = \frac{1}{Toj_j}\]
df_3_edit %>% summarise(sr1 = cor(y, x1_star),
sy = sd(y),
s1_star = sd(x1_star),
b1 = sr1 * (sy/s1_star),
#' Teil b: s_b_1
N = nrow(df_3),
sqrt_QS1_star = s1_star * sqrt(N-1),
QS1_star = sqrt_QS1_star^2,
sb1 = s_e / sqrt_QS1_star,
#' Teil c: Beta 1
s1 = sd(x1),
beta1 = b1 * (s1 / sy),
#' Teil d: t-Wert
t_val = b1 / sb1,
#' Teil e: p-Wert
p_val = pt(t_val, df = N-3-1, lower.tail = FALSE)*2,
#' Teil f, g: KI UG, OG
t_krit = qt(p = 0.975, df = deg_free),
KI_UG = b1 - t_krit * sb1,
KI_OG = b1 + t_krit * sb1,
#' Aufg. 3b) VIF bzw. Tol
QS1 = (s1^2) * (N-1),
VIF = QS1 / QS1_star,
Tol = 1/VIF) -> df_3_stat
df_3_stat %>% select(VIF, Tol) %>% round(3) VIF Tol
1 1.702 0.587Mit R lässt sich der VIF mittels vif()-Funktion aus dem car-Paket berechen:
VIF Tol
x1 1.702 0.587
x2 1.691 0.591
x3 1.022 0.978The VIF of a predictor is a measure for how easily it is predicted from a linear regression using the other predictors
Teilaufgabe c
Redundanz als mögliche Erklärung wirkt zunächst plausibel, allerdings hat \(x_3\) die höchste Toleranz \(Tol_{x_3} = 0.97\), d.h. völlig eigenständige Variable, die aber niedrige Korrelation mit AV hat (aber: die anderen beiden Variablen sind nicht dafür verantwortlich, dass diese Korrelation so gering ist!)
car::vif(mdl_1) x1 x2 x3
1.702403 1.691458 1.022267 Aufgabe 4
t-Test partielle Korrelation
$estimate
x1 x2 x3 y
x1 1.00000000 -0.48494555 0.087233274 0.215580398
x2 -0.48494555 1.00000000 -0.035821089 -0.389733364
x3 0.08723327 -0.03582109 1.000000000 -0.006430766
y 0.21558040 -0.38973336 -0.006430766 1.000000000
$p.value
x1 x2 x3 y
x1 0.0000000 0.2232266 0.8372655 0.6081360
x2 0.2232266 0.0000000 0.9328929 0.3398749
x3 0.8372655 0.9328929 0.0000000 0.9879426
y 0.6081360 0.3398749 0.9879426 0.0000000
$statistic
x1 x2 x3 y
x1 0.0000000 -1.35827208 0.21449468 0.54077777
x2 -1.3582721 0.00000000 -0.08779974 -1.03661540
x3 0.2144947 -0.08779974 0.00000000 -0.01575242
y 0.5407778 -1.03661540 -0.01575242 0.00000000
$n
[1] 10
$gp
[1] 2
$method
[1] "pearson"# t = 0.541
# p = .608t-Test Regression
summary.lm(mdl_1)
Call:
lm(formula = y ~ x1 + x2 + x3, data = df_3)
Residuals:
Min 1Q Median 3Q Max
-1.5060 -0.9447 -0.3618 0.6597 2.1757
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.156029 3.869435 1.849 0.114
x1 0.300670 0.555995 0.541 0.608
x2 -0.318334 0.307090 -1.037 0.340
x3 -0.005382 0.341653 -0.016 0.988
Residual standard error: 1.617 on 6 degrees of freedom
Multiple R-squared: 0.3699, Adjusted R-squared: 0.05488
F-statistic: 1.174 on 3 and 6 DF, p-value: 0.3949# t = 0.541
# p = .608Fußnoten
R gibt diesen Wert nicht standardmäßig aus, er muss im Gegensatz zu SPSS wie oben aufgeführt berechnet werden.↩︎