Mediationsmodelle knüpfen inhaltlich an dem Post von letzter Woche an.
Im Vergleich zum einfachen Regressionsmodell (links)…
…können Mediationsmodelle wie folgt beschrieben werden:
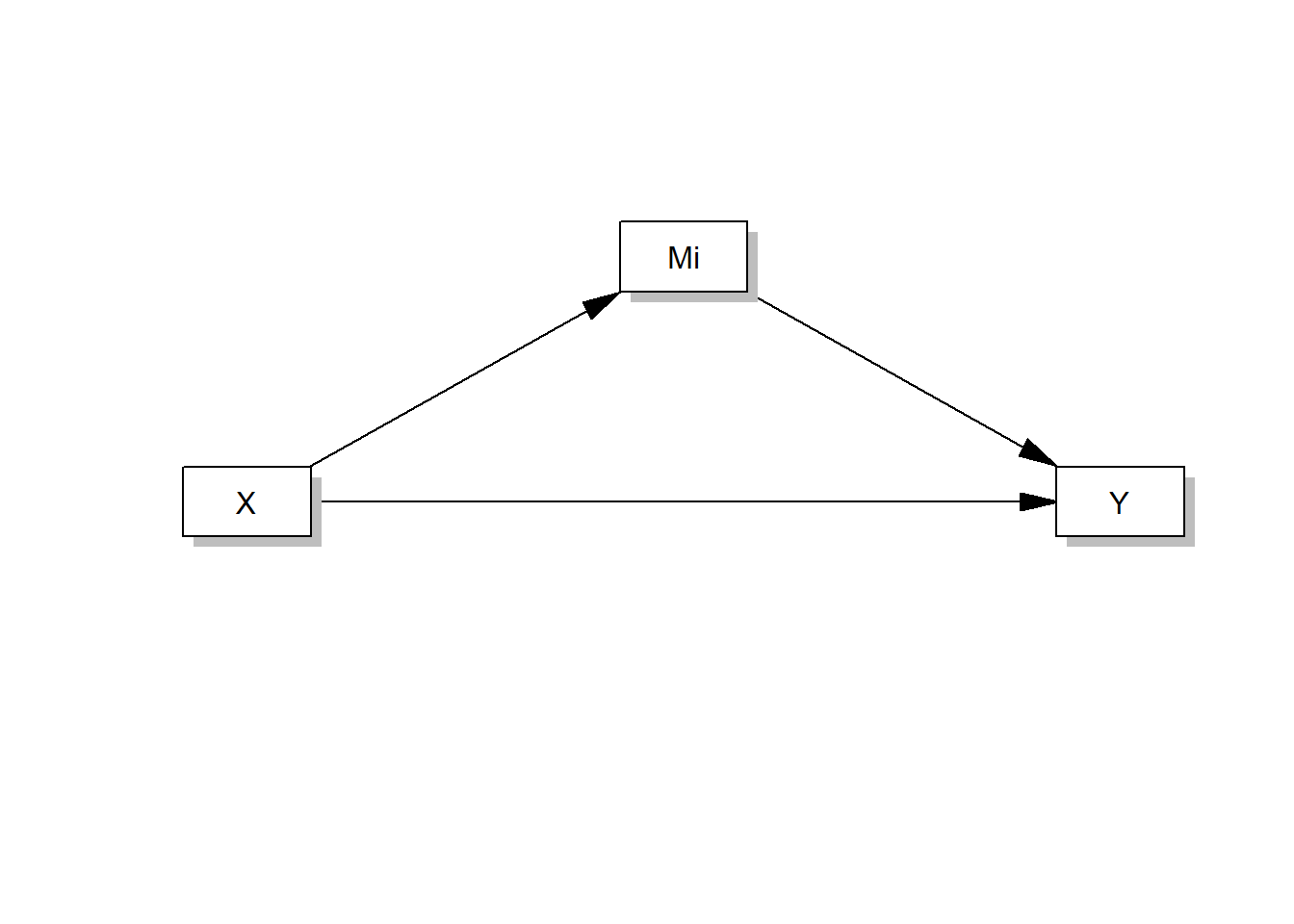
\[ \small \begin{align*} M = i_M + aX + eM \\ Y = i_Y + c'X + bM + e_Y \end{align*} \]
Beispiel
Die Variable Kampagne dient der Information über gesunde Ernährung (dummy-codiert: 0 = nicht informiert, 1 = informiert), wobei angenommen wird, dass sie das Verhalten vorhersagt.
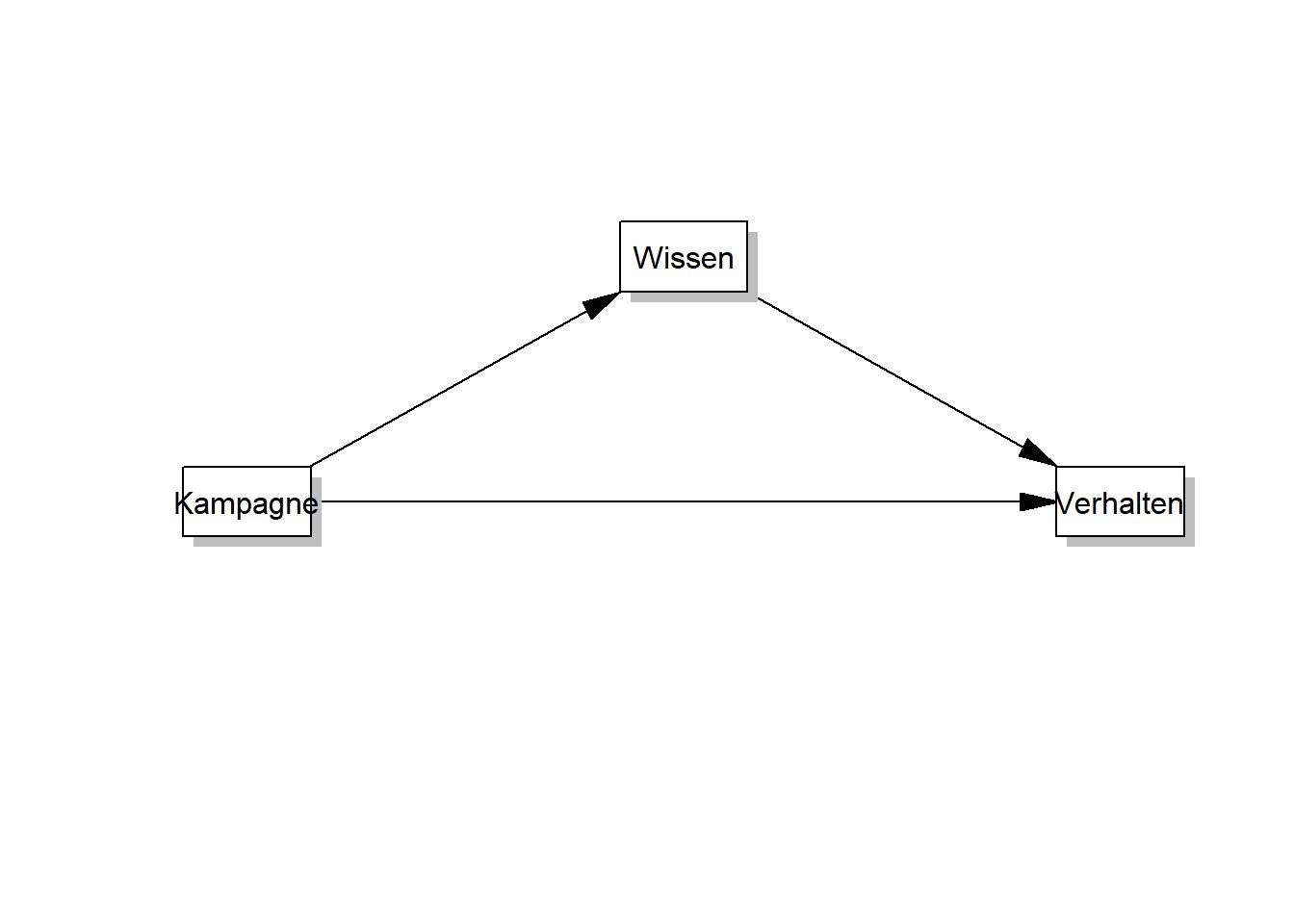
Angenommen Y (Verhalten) soll durch X (Kampagne) vorhergesagt werden, mit einem möglichen Mediator M (Wissen), dann ergeben sich folgende beiden Regressionsmodelle:
Vorhersage von a
Vorhersage von c’
totaler Effekt (c)
Vorhersage von Y durch X
Pakete
Übungsaufgaben
Aufgabe 1
Erläuterung
Im Buch (Hayes, 2022, S. 88) findet sich nachfolgende Beschreibung:
To illustrate the estimation of direct and indirect effects in a simple mediation model, I use data from a study conducted in Tal-Or et al. (2010). The data file is named
PMIand can be downloaded from this book’s webpage. The participants in this study (\(43\) male and \(80\) female students studying political science or communication at a university in Israel) read one of two newspaper articles describing an economic crisis that might affect the price and supply of sugar in Israel. Approximately half of the participants (\(n = 58\)) were given an article they were told would be appearing on the front page of a major Israeli newspaper (henceforth referred to as the front page condition). The remaining participants (\(n = 65\)) were given the same article but were told it would appear in the middle of an economic supplement of this newspaper (referred to here as the interior page condition). Which of the two articles any participant read was determined by random assignment. In all other respects, the participants in the study were treated equivalently, the instructions they were given were the same, and all measurement procedures were identical in both experimental conditions.
After the participants read the article, they were asked a number of questions about their reactions to the story. Some questions asked participants how soon they planned on buying sugar and how much they intended to buy. Their responses were aggregated to form an intention to buy sugar measure (
REACTIONin the data file), such that higher scores reflected greater intention to buy sugar (sooner and in larger quantities). They were also asked questions used to quantify how much they believed that others in the community would be prompted to buy sugar as a result of exposure to the article, a measure of presumed media influence (PMIin the data file).
Daten
df_med <- read_sav(here("data", "medreg", "pmi.sav")) %>%
haven::zap_labels() %>%
haven::zap_formats() %>%
mutate(cond = factor(cond, levels = c(0, 1),
labels = c("interior page", "front page")),
gender = factor(gender, levels = c(0, 1),
labels = c("female", "male")))
#' cond
#' 0 = interior page
#' 1 = front page
#' gender
#' 0 = female,
#' 1 = maleTeilaufgabe a
| M | SD | |
|---|---|---|
| interior page | 3.25 | 1.61 |
| front page | 3.75 | 1.45 |
Teilaufgabe b
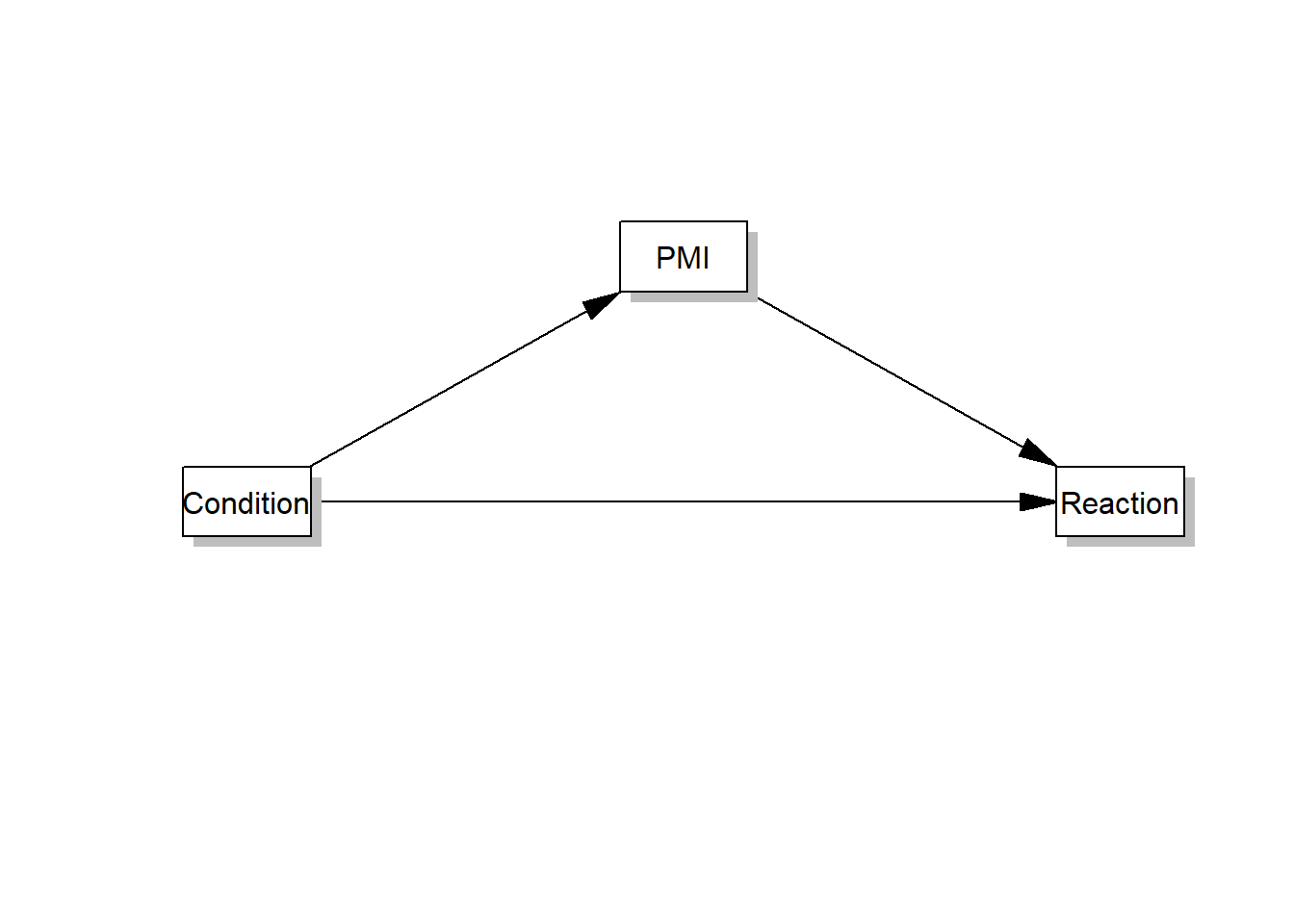
Zwei Regressionen:
- M wird vorhergesagt durch X;
- Y wird vorhergesagt durch X und M
\[ \small \begin{align*} M = i_M + aX + eM \\ Y = i_Y + c'X + bM + e_Y \end{align*} \] In unserem Fall ist
- M = PMI
- X = Condition
- Y = Reaction
Entsprechend gilt:
\[ \small \begin{align*} Y_{REACTION} = i_Y + c'X_{Condition} + bM_{PMI} + e_Y \\ M_{PMI} = i_M + aX_{Condition} + eM \end{align*} \]
coef(reg_1) (Intercept) condfront page
5.3769231 0.4765252 Also ist \(a=0.476\).
coef(reg_2) (Intercept) condfront page pmi
0.5268655 0.2543542 0.5064485 Sowie \(b = 0.506\) und \(c' = 0.254\)
Teilaufgabe c
Der direkte Effekt ist \(c' = 0.254\) (vgl. Output oben). Der indirekte Effekt ergibt sich als \(a\times b = 0.476 \times 0.506 = 0.241\), muss also berechnetet werden:
reg_1 %>% summary() %>%
broom::tidy() %>%
filter(term != "(Intercept)") %>%
select(a = estimate, se_a = std.error) -> desc_a
reg_2 %>% summary() %>%
broom::tidy() %>%
filter(term != "(Intercept)" & term != "condfront page") %>%
select(b = estimate, se_b = std.error) %>%
bind_cols(desc_a) %>%
mutate(ab = a*b) -> desc_ab
desc_ab %>% pull(ab) -> ab
round(ab, 3)[1] 0.241Teilaufgabe d
-
a=0.476: ist die Veränderung von \(M\) (
PMI), wenn \(X\) (COND) um eine Einheit steigt, d.h. also wenn man statt Gruppe 0 in Gruppe 1 ist. Folglich ist a der erwartete unterschied in der wahrgenommenen Nachfrage nach Zucker, der dadurch zustande kommt, dass sich die Condition unterscheidet, also eine Person in der erste-Seite-Bedingung statt in der innere-Seite-Bedingung ist. -
b=0.506: ist die erwartete Zunahme in der Intention Zucker zu kaufen (ob und wie viel Zucker gekauft wird) wenn sie sich in der vermuteten Nachfrage anderer nach Zucker um eine Einheit unterscheiden, sofern nur Personen einer Bedingung (
COND) betrachtet werden. -
c’=0.254: der direkte Effekt der
CONDauf dieREACTION: c’ ist die erwartete Zunahme der Intention einer Person der Erste-Seite-Bedingung vs. der innere-Seite-Bedingung Zucker zu kaufen, falls die wahrgenommene Nachfrage konstant ist. -
ab=0.243: der indirekte Effekt der
CONDauf dieREACTION: ab ist der erwartete Unterschied einer Person in der erste-Seite-Bedingung vs. einer Person in der innere-Seite-Bedingung in der Intention Zucker zu kaufen, der sich dadurch ergibt, dass die Person in der erste-Seite-Bedingung von einer erhöhten Nachfrage ausgeht.
Teilaufgabe e
Der totale Effekt ist die Summe von direkten und indirektem Effekt (d.h. die Entscheidung Zucker zu kaufen, egal welcher Mechanismus eine Rolle spiele, sprich pmi wird nicht in der Modell lm(reaction ~ cond) aufgenommen): indirekter Effekt + direkter Effekt = \(c' + ab = 0.254 + 0.243 = 0.495\)
Der Mittelwertsunterschied in meiner Intention Zucker zu kaufen im Vergleich beider Gruppen. D.h. es können auch beide Mittelwerte der Gruppen vergleichen werden:
Teilaufgabe f
Für die Berechnung von \(SE_{ab}\) werden also \(a\), \(b\) und deren Standardfehler benötigt. Diese haben wir bereits oben in desc_ab abgespeichert.
Teilaufgabe g
Wir berechnen \(z=ab/SE_{ab}\)
z <- ab / se_ab
z[1] 1.855877Dabei ist \(z_{emp}=1.86\) weniger extrem als der kritische z-Wert \(z_{krit}=1.96\)
z > qnorm(p = .975)[1] FALSETeilaufgabe h
# CI = ab +- 1.96 * SE
ab - qnorm(p = .975) * se_ab[1] -0.01353528ab + qnorm(p = .975) * se_ab[1] 0.4962062Damit ist \(ab=0.241\), \(95\%KI=[-0.013, 0.496]\).
Aufgabe 2
Teilaufgabe a
Frei nach unserem Motto nutzen wir selbstverständlich R; konkret das 📦 mediation-Paket1.
set.seed(123)
results <- mediation::mediate(model.m = reg_1, model.y = reg_2,
treat = 'cond', mediator = 'pmi', boot = FALSE)
summary(results)
Causal Mediation Analysis
Quasi-Bayesian Confidence Intervals
Estimate 95% CI Lower 95% CI Upper p-value
ACME 0.2429 0.0157 0.53 0.044 *
ADE 0.2459 -0.2571 0.75 0.330
Total Effect 0.4888 -0.0964 1.04 0.082 .
Prop. Mediated 0.4726 -0.7557 2.51 0.118
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Sample Size Used: 123
Simulations: 1000 Die Terme haben folgende Bedeutung:
- ACME: indirekter Effekt \(ab\)
- ADE: direkter Effekt \(c'\)
- Total Effect: totaler Effekt \(c' + ab\) (aka. Gesamteffekt)
- Prop. Mediated: mediierter Anteil (proportions mediated)2; Größe der durchschnittlichen kausalen Mediationsaffekte im Verhältnis zum Gesamteffekt
Teilaufgabe b
# default: sims = 1000; aber normal = 1 fehlt
results_ci <- mediation::mediate(model.m = reg_1, model.y = reg_2, sims = 5000,
treat = 'cond', mediator = 'pmi', boot = TRUE)
summary(results_ci)
Causal Mediation Analysis
Nonparametric Bootstrap Confidence Intervals with the Percentile Method
Estimate 95% CI Lower 95% CI Upper p-value
ACME 0.2413 0.0108 0.53 0.044 *
ADE 0.2544 -0.2614 0.76 0.330
Total Effect 0.4957 -0.0503 1.04 0.076 .
Prop. Mediated 0.4869 -0.8844 2.85 0.104
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Sample Size Used: 123
Simulations: 5000 Literatur
Hayes, A. F. (2022). Introduction to mediation, moderation, and conditional process analysis: A regression-based approach (3. Aufl.). Guilford Publications.
Tal-Or, N., Cohen, J., Tsafati, Y., & Gunther, A. C. (2010). Testing causal direction in the influence of presumed media influence. Communication Research, 37(6), 801–824. https://doi.org/10.1177/0093650210362684