Pakete
Theorie
Die drei Arten von Konfidenzintervallen für Differenzen von Mittelwerten zwischen den Gruppen \(\small A\) und \(\small B\), \(\small \mu_{iA}-\mu_{iB}\) für \(\small i=1,...,p\), besitzen eine gemeinsame Form. Diese lautet:
\[ \small \underbrace{\bar{x}_{iA}-\bar{x}_{iB}}_{\Delta} ~\pm \underbrace{\sqrt{s_i^2(\frac{n_1+n_2}{n_1n_2})}}_{SE} \cdot \underbrace{t_{krit}}_{Quantil} \]
Nur der kritische Wert muss angepasst werden. Es gilt:
- Univariat: \(\small t_{krit}=t_{1-\alpha/2}\) mit \(\small df_t=n_1+n_2-2\) Freiheitsgraden
- Bonferroni: \(\small t_{krit}=t_{1-\alpha/(2p)}\) mit \(\small df_t=n_1+n_2-2\) Freiheitsgraden
- Roy: \(\small t_{krit}= \sqrt{T^2_{krit}}\) mit \(\small df_1=n_1+n_2-2\) Freiheitsgraden
Der kritische Wert für Roy-Intervalle wird über die F-Verteilung ermittelt. Und zwar gilt:
\[\small T_{krit}^2 = \frac{(n_1+n_2-2)p}{n_1+n_2-p-1}\cdot F_{1-\alpha}\] mit \(\small df_{F}=p, n_1+n_2-p\) Freiheitsgraden
Übungsaufgaben
Aufgabe 1
Daten
Code
df_t3 <- haven::read_sav(here("data", "hotellings_T", "t3daten.sav")) %>%
janitor::clean_names() %>%
haven::zap_formats() %>%
haven::zap_widths() %>%
haven::zap_labels()
df_lng <- df_t3 %>%
rename(diagnosis_father = grp) %>%
pivot_longer(cols = c(x1, x2),
names_to = c("test_child")) %>%
mutate(test_child = stringr::str_remove(test_child, "x"),
test_child = as.numeric(test_child),
test_child = factor(test_child, levels = c(1, 2),
labels = c("anxiety", "depression")),
diagnosis_father = factor(diagnosis_father, levels = c(1, 2),
labels = c("schizophrenic",
"not schizophrenic")))Teilaufgabe a
df_stat <- df_lng %>%
group_by(test_child, diagnosis_father) %>%
summarise(M = mean(value),
SD = sd(value),
n = n())
df_stat# A tibble: 4 × 5
# Groups: test_child [2]
test_child diagnosis_father M SD n
<fct> <fct> <dbl> <dbl> <int>
1 anxiety schizophrenic 13 2.83 7
2 anxiety not schizophrenic 10.1 1.17 9
3 depression schizophrenic 20 1.29 7
4 depression not schizophrenic 20.8 1.30 9df_lbl <- df_stat %>% rename(father = diagnosis_father)
df_lng %>% rename(father = diagnosis_father) %>%
ggplot(aes(x = test_child, y = value)) +
geom_violin(aes(fill = test_child),
trim = FALSE,
show.legend = FALSE,
alpha = .5) +
geom_boxplot(width = 0.1, alpha = .5) +
geom_point(aes(x = test_child, y = M,
# shape = test_child,
# color = fill = test_child,
fill = test_child),
shape = 23, #21,
size = 2,
data = df_lbl) +
scale_fill_brewer(palette = "Accent") +
# scale_color_brewer("mean", palette = "Accent") +
facet_wrap(~father,
labeller = labeller(father=label_both)) +
labs(# shape = "arithmetic\nmean",
fill = "arithmetic mean",
x = "child: test",
y = "test score") +
theme_bw()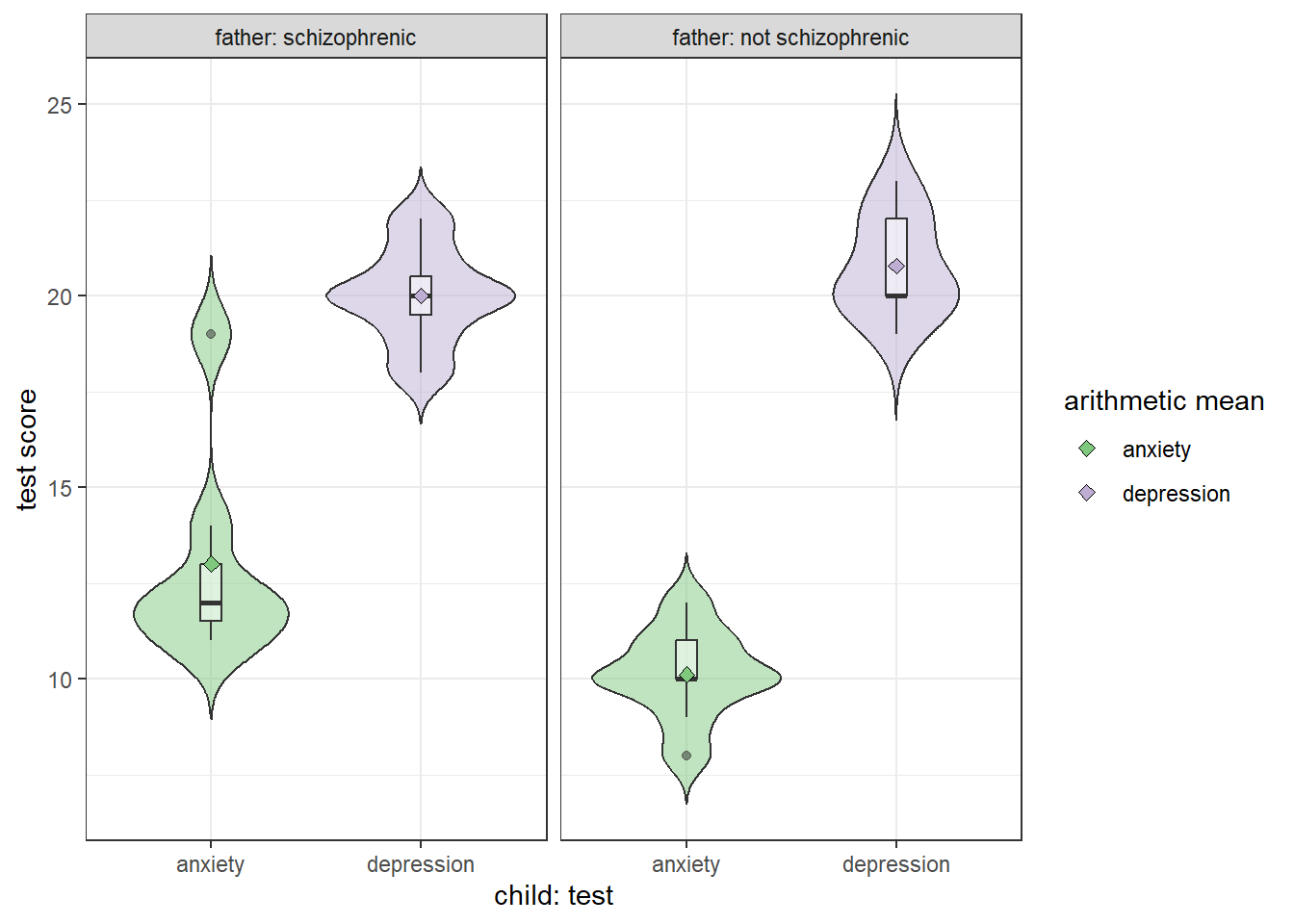
Teilaufgabe b
mdl1 <- lm(cbind(x1, x2) ~ grp, data = df_t3)
fit1 <- Manova(mdl1) #, test.statistic = "Hotelling-Lawley")
summary(fit1)
Type II MANOVA Tests:
Sum of squares and products for error:
x1 x2
x1 58.88889 13.22222
x2 13.22222 23.55556
------------------------------------------
Term: grp
Sum of squares and products for the hypothesis:
x1 x2
x1 32.861111 -8.847222
x2 -8.847222 2.381944
Multivariate Tests: grp
Df test stat approx F num Df den Df Pr(>F)
Pillai 1 0.4864354 6.156637 2 13 0.013148 *
Wilks 1 0.5135646 6.156637 2 13 0.013148 *
Hotelling-Lawley 1 0.9471749 6.156637 2 13 0.013148 *
Roy 1 0.9471749 6.156637 2 13 0.013148 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Teilaufgabe c
HS <- manova(mdl1) %>%
summary.manova(test = "Hotelling-Lawley") %$%
Eigenvalues[,1]
HS grp
0.9471749 df_t3 %>% group_by(grp) %>% count() %>%
pivot_wider(names_from = grp, values_from = n, names_prefix = "n") %>%
mutate(p = ncol(.), # p = Anzahl AVs
HS = HS) -> df_ni
df_ni %>% summarise(T_sq = (n1+n2-2) * HS,
df_1 = p,
df_2 = n1+n2-p-1)# A tibble: 1 × 3
T_sq df_1 df_2
<dbl> <int> <dbl>
1 13.3 2 13Teilaufgabe d
summary(mdl1)Response x1 :
Call:
lm(formula = x1 ~ grp, data = df_t3)
Residuals:
Min 1Q Median 3Q Max
-2.1111 -1.0278 -0.1111 0.8889 6.0000
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 15.889 1.694 9.377 2.06e-07 ***
grp -2.889 1.034 -2.795 0.0143 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.051 on 14 degrees of freedom
Multiple R-squared: 0.3582, Adjusted R-squared: 0.3123
F-statistic: 7.812 on 1 and 14 DF, p-value: 0.01432
Response x2 :
Call:
lm(formula = x2 ~ grp, data = df_t3)
Residuals:
Min 1Q Median 3Q Max
-2.0000 -0.7778 0.0000 1.0556 2.2222
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 19.2222 1.0716 17.94 4.68e-11 ***
grp 0.7778 0.6537 1.19 0.254
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.297 on 14 degrees of freedom
Multiple R-squared: 0.09183, Adjusted R-squared: 0.02697
F-statistic: 1.416 on 1 and 14 DF, p-value: 0.2539Mittelwerte der Gruppe schizophren ergeben sich als:
- AV Angst:
Intercept+grp= 15.889 - 2.889 = 13 - AV Depression:
Intercept+grp= 19.2222 + 0.7778 = 20
grp ist dabei der Gruppenmittelwertsunterschied. Entsprechend geben sich die Mittelwerte der Gruppe nicht schizophren als:
- AV Angst: 13 - 2.889 = 10.11
- AV Depression: 20 + 0.7778 = 20.78
Die AV Angst unterscheidet sich demnach signifikant zwischen beiden Gruppen (p < .05), nicht aber die mittlere Ausprägung der AV Depression.
Teilaufgabe e
Call:
lm(formula = x1 ~ z, data = df_t3)
Residuals:
Min 1Q Median 3Q Max
-2.1111 -1.0278 -0.1111 0.8889 6.0000
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 10.1111 0.6836 14.790 6.13e-10 ***
z 2.8889 1.0336 2.795 0.0143 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.051 on 14 degrees of freedom
Multiple R-squared: 0.3582, Adjusted R-squared: 0.3123
F-statistic: 7.812 on 1 and 14 DF, p-value: 0.01432Teilaufgabe f
confint(mdl1) 2.5 % 97.5 %
x1:(Intercept) 12.2547567 19.523021
x1:grp -5.1056887 -0.672089
x2:(Intercept) 16.9237952 21.520649
x2:grp -0.6242496 2.179805Die F-Statistik der MANOVA zeigte einen signifikanten Unterschied für mindestens eine der beiden abhängigen Variablen an, \(\small F(2, 13) = 6.16\), \(\small p <.05\). Dieser ist auf den Gruppenmittelwertsunterschied der ersten AV Angst zurückzuführen, für die Gruppenmittelwertunterschide der AV Depression konnte kein signifikanter Unterschied gezeigt werden (vgl. Output: 0 in 95%KI enthalten).
Teilaufgabe g
Benötigt werden Differenz, Standardfehler und kriterischer t-Wert:
\[ \small \underbrace{\bar{x}_{iA}-\bar{x}_{iB}}_{\Delta} ~\pm \underbrace{\sqrt{s_i^2(\frac{n_1+n_2}{n_1n_2})}}_{SE} \cdot \underbrace{t_{krit}}_{Quantil} \]
Den Standardfehler der Mittelwertdifferenzen müssen wir wiederum erst ausrechnen, ich habe die Formel dafür in die nachfolgende Funktion eingesetzt, um etwas Arbeit zu sparen:
Mit se_pooled können wir nun das univariate KI berechnen: \(\small t_{krit}=t_{1-\alpha/2}\) mit \(\small df_t=n_1+n_2-2\) Freiheitsgraden
df_KI <- df_stat %>%
mutate(diagnosis_father = as.numeric(diagnosis_father)) %>%
pivot_wider(values_from = c(M, SD, n),
names_from = diagnosis_father) %>%
mutate(SE = se_pooled(n_1, n_2, SD_1, SD_2),
delta = M_1 - M_2,
p = nrow(.),
alpha = .05,
t_krit = qt(p = alpha/2,
df = (n_1+n_2-2), lower.tail = FALSE),
KI_UG_univ = delta - SE * t_krit,
KI_OG_univ = delta + SE * t_krit)
df_KI %>% select(test_child, delta, starts_with("KI"))| delta | 95% KI | |
|---|---|---|
| anxiety | 2.89 | 0.67, 5.11 |
| depression | −0.78 | −2.18, 0.62 |
Teilaufgabe h
Die Konfidenzintervalle lassen sich über die oben gegebenen Formeln berechnen:
- Bonferroni: \(\small t_{krit}=t_{1-\alpha/(2p)}\) mit \(\small df_t=n_1+n_2-2\) Freiheitsgraden
- Roy: \(\small t_{krit}= \sqrt{T^2_{krit}}\) via F-Verteilung: \(\small T_{krit}^2 = \frac{(n_1+n_2-2)p}{n_1+n_2-p-1}\cdot F_{1-\alpha}\) mit \(\small df_{F}=p, n_1+n_2-p\) Freiheitsgraden
df_KI %>% mutate(t_krit_bonf = qt(p = alpha/(2*p),
df = (n_1+n_2-2),
lower.tail = FALSE),
KI_UG_bonf = delta - SE * t_krit_bonf,
KI_OG_bonf = delta + SE * t_krit_bonf,
F_krit_roy = qf(p = alpha,
lower.tail = FALSE,
df1 = p,
df2 = n_1+n_2-p),
Tsq_krit_roy = (((n_1 + n_2 - 2)*p)/
(n_1 + n_2 - p - 1))*F_krit_roy,
t_krit_roy = sqrt(Tsq_krit_roy),
KI_UG_roy = delta - SE * t_krit_roy,
KI_OG_roy = delta + SE * t_krit_roy) -> df_KI
df_KI %>% select(test_child, delta, starts_with("KI")) %>%
pivot_longer(col = starts_with("KI"),
names_pattern = "KI_(.*)_(.*)",
names_to = c("border", "type")) -> df_KI_lng
df_KI_lng %>% pivot_wider(names_from = border, values_from = value) -> df_KI_wd| delta | UG | OG | |
|---|---|---|---|
| anxiety | |||
| univ. | 2.89 | 0.67 | 5.11 |
| bonf. | 2.89 | 0.30 | 5.48 |
| roy | 2.89 | −0.04 | 5.82 |
| depression | |||
| univ. | −0.78 | −2.18 | 0.62 |
| bonf. | −0.78 | −2.42 | 0.86 |
| roy | −0.78 | −2.63 | 1.08 |
df_KI_wd %>% ggplot(aes(x = type, y = delta)) +
geom_pointrange(aes(ymin = UG, ymax = OG)) +
geom_hline(yintercept = 0, linetype = 3) +
coord_flip() +
facet_wrap(~test_child, scales = "free_x") +
labs(x = "CI Type") +
theme_bw()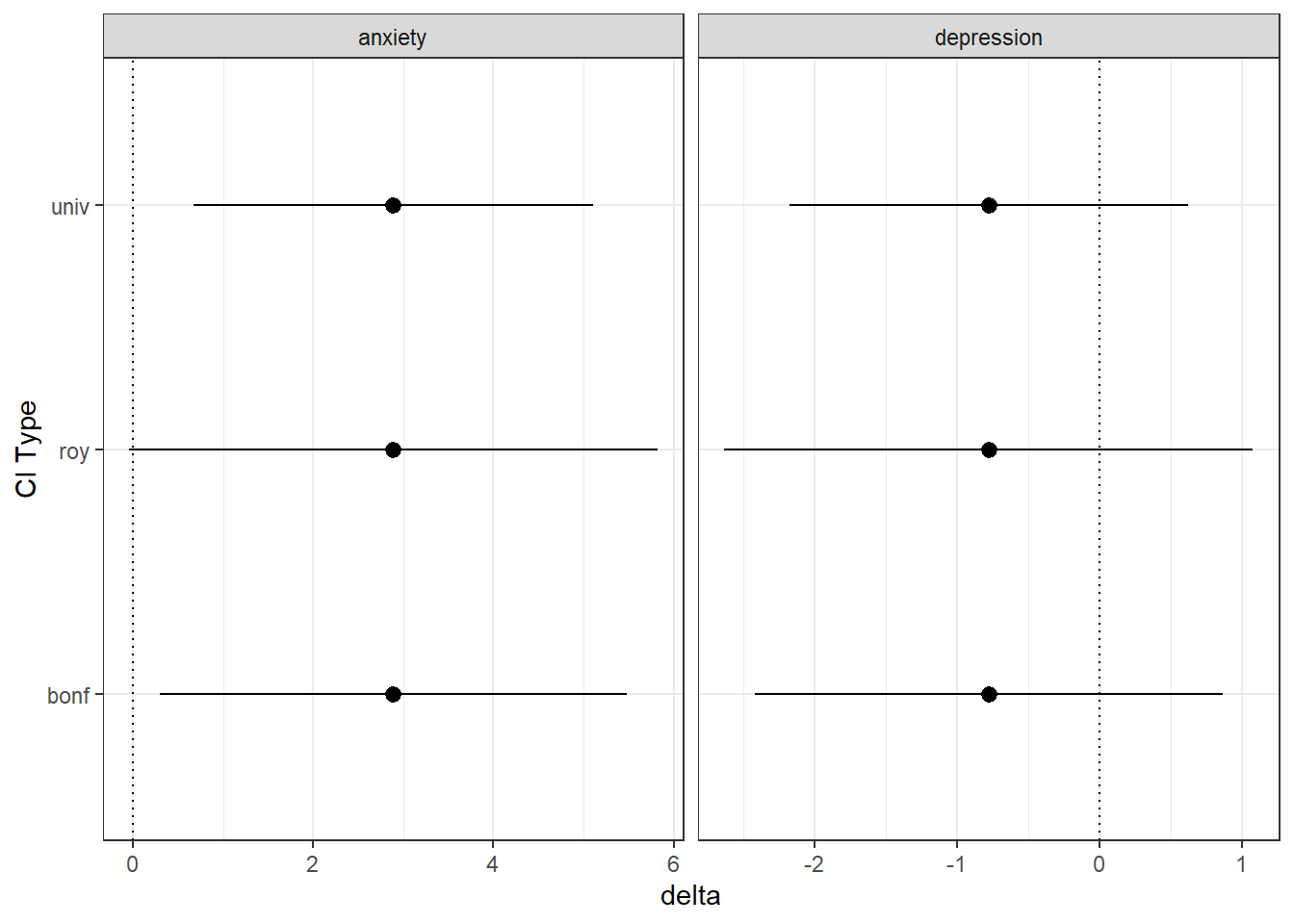
Teilaufgabe i
Aufgabe 2
Teilaufgabe a
Eine minimale Anpassung der Synatax ergibt für die \(\small \mathbf{D_1}\) Matrix:
Analog ergibt sich \(\small \mathbf{D_1}\) über:
Teilaufgabe b
Mit den \(\small \mathbf{D}\)-Matrizen lassen sich die \(\small \mathbf{W}\)- und \(\small \mathbf{S}\)-Matrix berechnen:
W <- D1+D2; W [,1] [,2]
[1,] 58.88889 13.22222
[2,] 13.22222 23.55556S <- 1/(n1+n2-2) * W; S [,1] [,2]
[1,] 4.2063492 0.9444444
[2,] 0.9444444 1.6825397Damit lässt sich dann wiederum \(\small T^2_3\) wie folgt berechnen: