Pakete
Übungsaufgaben
Aufgabe 1
Daten
df_adopt <- tribble(~"x1", ~"x2",
142, 123,
105, 92,
117, 121,
133, 125,
114, 132,
120, 136,
96, 112,
108, 120,
129, 98,
114, 117)Teilaufgabe a
| Variablen | Kreuzprodukt | Quadratsummen | |||||
|---|---|---|---|---|---|---|---|
| x1 | x2 | x1-x̄1 | x2-x̄2 | (x1-x̄1)(x2-x̄2) | (x1-x̄1)2 | (x2-x̄2)2 | |
| 1 | 142 | 123 | 24.2 | 5.4 | 130.68 | 585.64 | 29.16 |
| 2 | 105 | 92 | -12.8 | -25.6 | 327.68 | 163.84 | 655.36 |
| 3 | 117 | 121 | -0.8 | 3.4 | -2.72 | 0.64 | 11.56 |
| 4 | 133 | 125 | 15.2 | 7.4 | 112.48 | 231.04 | 54.76 |
| 5 | 114 | 132 | -3.8 | 14.4 | -54.72 | 14.44 | 207.36 |
| 6 | 120 | 136 | 2.2 | 18.4 | 40.48 | 4.84 | 338.56 |
| 7 | 96 | 112 | -21.8 | -5.6 | 122.08 | 475.24 | 31.36 |
| 8 | 108 | 120 | -9.8 | 2.4 | -23.52 | 96.04 | 5.76 |
| 9 | 129 | 98 | 11.2 | -19.6 | -219.52 | 125.44 | 384.16 |
| 10 | 114 | 117 | -3.8 | -0.6 | 2.28 | 14.44 | 0.36 |
| Summe | 1,178.00 | 1,176.00 | — | — | 435.20 | 1,711.60 | 1,718.40 |
| Mittel | 117.80 | 117.60 | — | — | 43.52 | 171.16 | 171.84 |
Teilaufgabe b
Teilaufgabe c
D <- 9 * cov(df_adopt); D x1 x2
x1 1711.6 435.2
x2 435.2 1718.4Aufgabe 2
Die Syntax kann (leicht abgewandelt) angegeben werden:
Aufgabe 3
Teilaufgabe a
Teilaufgabe b
Wir haben \(\small p=2\) abhängige Variablen, entsprechend ergibt sich eine transformierte Prüfgröße als \(\small F=0.44\times T^2=11.66\):
p <- 2
trans_fac <- (n-p) / ((n-1)*p)
F_emp <- trans_fac * T_sq
round(F_emp, 3)[1] 11.657Da nicht anders angegeben, nehmen wir \(\small \alpha=.05\) an (wir benennen die Variable als alpha, da p bereits reserviert ist). Für einen zugehörigen Signifikanztest ergeben sich \(\small df_{Zähler}=2\) und \(\small df_{Zähler}=n-p=8\) Freiheitsgrade der F-Verteilung:
alpha <- 0.05
df_num <- p
df_denom <- n-p
F_krit <- qf(alpha/2, df1 = df_num, df2 = df_denom)
round(F_krit, 3)[1] 0.025F_emp > F_krit[1] TRUEFolglich gibt es einen signifikanten Unterschied zwischen \(\mu_0=100\) und einer oder beiden der abhängigen Variablen, \(\small F(2,8)=11.66\), \(\small p<.005\).
pf(q = F_emp, df1 = df_num, df2 = df_denom, lower.tail = FALSE)[1] 0.004259699Aufgabe 4
- Testen Sie die Hypothese “Die Adoptivkinder sind durchschnittlich intelligent” mit SPSS
GLM. Bemerkung: Da über das Menü der am Prozedur kein \(\mu_0\)-Vektor spezifiziert werden kann, müssen die Werte der Hypothese zuvor von den VariablenVIQundPIQsubtrahiert werden. Erzeugen Sie folgenden Output:
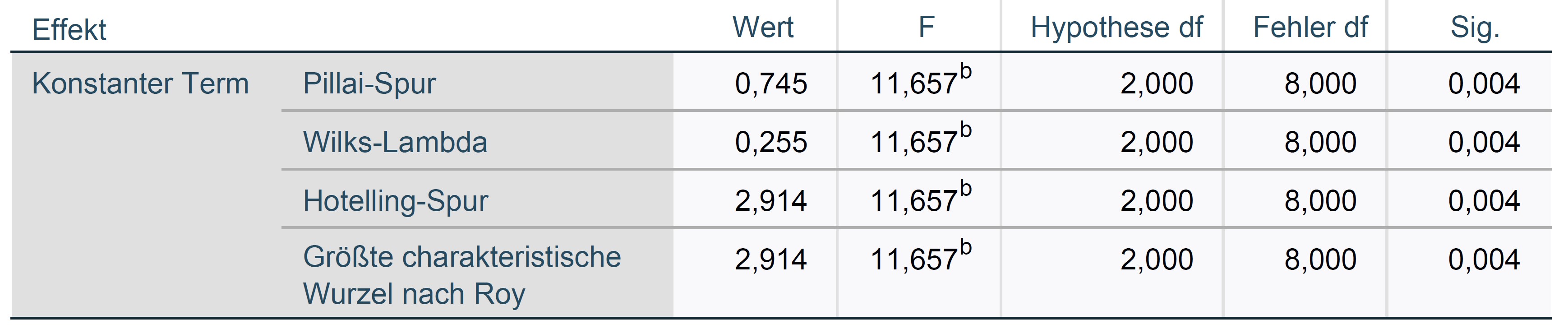
- Obwohl der F-Wert und der p-Wert für Hotellings Spur mit dem zuvor berechneten Werten übereinstimmen, ist der \(T_1^2\)-Wert nicht mit Hotellings Spur identisch. Wie sind Hotellings \(T_1^2\) und Hotellings Spur miteinander verknüpft?
Teilaufgabe a
df_mdl <- df_adopt %>% transmute(x1_d = x1-100, x2_d = x2-100)
model <- lm(cbind(x1_d, x2_d) ~ NULL, df_mdl)
fit <- car::Manova(model, type = "III", test.statistic = "Hotelling-Lawley")
summary(fit)
Type III MANOVA Tests:
Sum of squares and products for error:
x1_d x2_d
x1_d 1711.6 435.2
x2_d 435.2 1718.4
------------------------------------------
Term: (Intercept)
Sum of squares and products for the hypothesis:
x1_d x2_d
x1_d 3168.4 3132.8
x2_d 3132.8 3097.6
Multivariate Tests: (Intercept)
Df test stat approx F num Df den Df Pr(>F)
Pillai 1 0.7445272 11.65724 2 8 0.0042597 **
Wilks 1 0.2554728 11.65724 2 8 0.0042597 **
Hotelling-Lawley 1 2.9143105 11.65724 2 8 0.0042597 **
Roy 1 2.9143105 11.65724 2 8 0.0042597 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Teilaufgabe b
Wie SPSS bereichtet R nicht den T²-Wert, sondern Pillais Spur, Wilks Lambda, Hotelling-Lawley und Roy’s largest-latent root. Für alle Werte sind die sich daraus ergebenden F-Werte samt Freiheitsgraden und zugehörigen p-Werten identisch und stimmen auch mit den hier händisch berechneten Werten überein. Hotellings Spur und Hotelling T² stehen über den Faktor \(\small (n-1)\) in Relation:
T_sq / (n-1)[1] 2.914311