Pakete
Zur Durchführung von Faktoren- bzw. Hauptkomponentenanalysen existieren bereits Funktionen im stats-package (Base-R), nämlich factanal() bzw. princomp() und prcomp().
Darüber hinaus sind div. Funktionen über zusätzliche Pakete verfügbar, z. B.
-
PCA()aus dem 📦FactoMineR-Paket, -
dudi.pca()aus dem 📦ade4-Paket, -
print.expoOutput()aus dem 📦ExPosition-Paket, - etc.
Wir verwenden das 📦 psych-Paket, mit dessen Funktionen leicht ein zu SPSS vergleichbares Output erstellt werden kann:
Es existiert auch in diesem Paket eine Funktion principal() für die Hauptkomponentenanalyse und fa() als Pendant für die Faktorenanalyse.
In der Vorlesung wird keine Trennung zwischen beiden Analysemethoden gemacht1. In den Übungsaufgaben ist daher von Faktoren die Rede, obgleich Hauptkomponenten gemeint sind. Analog zum Seminar verwenden wir principal(). Das aufgeführte Pendant verfügt über dieselben relevanten Argumente:
- Anzahl an Faktoren:
nfactors(default 1) - Rotationsmethode:
rotate("none","varimax", …) - etc. (siehe
?principal,?fa)
Entsprechend ist die Nutzung von fa() ebenso möglich und führt zu vergleichbaren Ergebnissen.
Übungsaufgaben
Aufgabe 1
Daten
In der vorliegenden Stichprobe sind alle möglichen Dupel von Zylindern mit Durchmesser \(\small D=\{1,2,3\}\) und Länge \(\small L=\{2,3,4\}\) vorhanden. Diese Variablen sind somit unkorreliert; die übrigen Variablen erheben sich anhand der Tabelle:
- Durchmesser (\(\small d\)),
- Länge (\(\small l\)),
- Grundfläche (\(\small a=\pi d^2/4\))‚
- Mantelfläche (\(\small c=\pi dl\))‚
- Volumen (\(\small v=\pi d^2l/4\))‚
- Diagonale (\(\small t=\sqrt{d^2+l^2}\))
df_thurs <- tibble(d = rep(1:3, 3),
l = rep(2:4, each = 3)) %>%
mutate(a = pi * d^2 / 4,
c = pi * d * l,
v = pi * d^2 * l / 4,
t = sqrt(d^2 + l^2))
df_thurs# A tibble: 9 × 6
d l a c v t
<int> <int> <dbl> <dbl> <dbl> <dbl>
1 1 2 0.785 6.28 1.57 2.24
2 2 2 3.14 12.6 6.28 2.83
3 3 2 7.07 18.8 14.1 3.61
4 1 3 0.785 9.42 2.36 3.16
5 2 3 3.14 18.8 9.42 3.61
6 3 3 7.07 28.3 21.2 4.24
7 1 4 0.785 12.6 3.14 4.12
8 2 4 3.14 25.1 12.6 4.47
9 3 4 7.07 37.7 28.3 5 DATA LIST FREE /d l.
BEGIN DATA
1 2 2 2 3 2 1 3 2 3 3 3 1 4 2 4 3 4
1 2 2 2 3 2 1 3 2 3 3 3 1 4 2 4 3 4
1 2 2 2 3 2 1 3 2 3 3 3 1 4 2 4 3 4
END DATA.
DATASET NAME THURS.
COMPUTE PI = 3.141593.
COMPUTE a = PI * d**2 / 4.
COMPUTE c = PI * d * l.
COMPUTE v = PI * d**2 * l / 4.
COMPUTE d = SQRT(d**2 + l**2).
EXECUTE.Anmerkung. Da SPSS die Zahl Pi nicht kennt, muss diese erst als Variable angelegt werden. Soll diese neue Variable nicht im Datensatz auftauchen, kann dies über eine s.g. Scratch-Varibale erfolgen. Anstatt PI wird dann #PI im Synatax geschrieben.
Teilaufgabe a
Mit den Standardeinstellungen von SPSS wird die Anzahl an Faktoren mit Eigenwert \(\small \geq 1\) extrahiert (Kaiser-Kriterium). Dies ist mit der principal() Funktion aus dem 📦 psych-Paket nicht vergleichar, dort wird per default ein Faktor extrahiert (nfactors = 1 vgl. ?principal). Entsprechend bestimmen wird zunächst die Anzahl der Faktoren über den Eigenwert:
Code
| Komponente | Eigenwert |
|---|---|
| 1 | 4.435 |
| 2 | 1.459 |
| 3 | 0.087 |
| 4 | 0.018 |
| 5 | 0.000 |
| 6 | 0.000 |
Code
df_eigen %>% ggplot(aes(x = x, y = val)) +
geom_hline(yintercept = 1, color = "red") +
geom_point() +
geom_line(linetype = 3) +
labs(x = "Komponente", y = "Eigenwert", title = "Scree-Plot") +
theme_bw()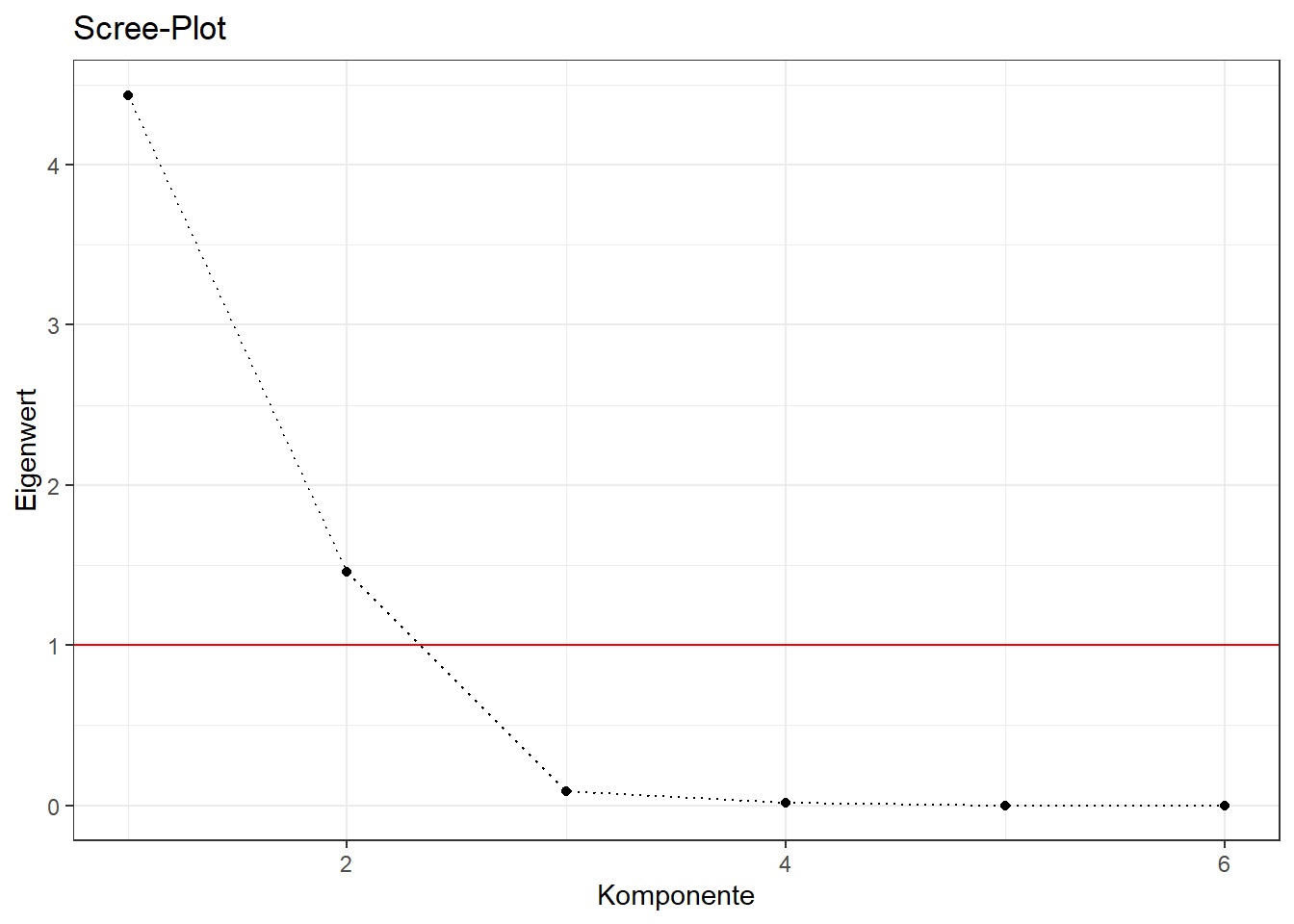
Es haben \(\small p=2\) Komponenten Eigenwerte größer 1, entsprechend extrahieren wir zwei Faktoren (vgl. Scree-Plot links vom “Knick”). Außerdem setzen wird rotate = "none", um ein vergleichbares Output zu erhalten (SPSS nutzt per default keine Rotation).
pca_2 <- principal(df_thurs, nfactors = 2, rotate = "none") Die einzelnen Tabellen des SPSS-Outputs lassen sich wie folgt replizieren:
pca_2$loadingsCode
| 1 | 2 | |
|---|---|---|
| d | 0.881 | -0.458 |
| l | 0.461 | 0.887 |
| a | 0.881 | -0.459 |
| c | 0.983 | 0.100 |
| v | 0.978 | -0.115 |
| t | 0.864 | 0.478 |
pca_2$values; pca_2$VaccountedCode
cap_2 <- "Erklärte Gesamtvarianz"
pca_2 %$% data.frame(comp = 1:length(values),
total = values) %>%
mutate(var = (total/max(comp))*100,
cuml = cumsum(var)) %>%
kbl(booktabs = TRUE,
digits = 3,
align = "lrrr",
caption = cap_2,
col.names = c("Komponente",
"Gesamt",
"% der Varianz",
"Kummulierte %")) %>%
add_header_above(., c("",
"Anfängliche Eigenwerte" = 3)) %>%
kable_paper("hover",
full_width = F)| Komponente | Gesamt | % der Varianz | Kummulierte % |
|---|---|---|---|
| 1 | 4.435 | 73.922 | 73.922 |
| 2 | 1.459 | 24.315 | 98.237 |
| 3 | 0.087 | 1.450 | 99.687 |
| 4 | 0.018 | 0.303 | 99.990 |
| 5 | 0.000 | 0.006 | 99.997 |
| 6 | 0.000 | 0.003 | 100.000 |
Code
hdr_2 <- c("",
"Summen von quadierter
Faktorladungen für Extraktion" = 3)
pca_2 %$% Vaccounted %>%
data.frame() %>%
rownames_to_column() %>%
filter(rowname == "SS loadings") %>%
pivot_longer(cols = starts_with("PC"),
names_to = "comp",
names_prefix = "PC") %>%
select(-rowname) %>%
mutate(comp = as.numeric(comp),
var = (value/6)*100,
cuml = cumsum(var)) %>%
kbl(booktabs = TRUE,
digits = 3,
align = "lrrr",
col.names = c("Komponente",
"Gesamt",
"% der Varianz",
"Kummulierte %")) %>%
add_header_above(., hdr_2) %>%
kable_paper("hover",
full_width = F)| Komponente | Gesamt | % der Varianz | Kummulierte % |
|---|---|---|---|
| 1 | 4.435 | 73.922 | 73.922 |
| 2 | 1.459 | 24.315 | 98.237 |
pca_2$communality Code
cap_3 <- "Kommunalitäten"
col_3 <- c("Anfänglich",
"Extraktion")
pca_2$communality %>%
data.frame(strt = 1,
extr = .) %>%
kbl(booktabs = TRUE,
digits = 3,
align = "r",
caption = cap_3,
col.names = col_3) %>%
kable_paper("hover",
full_width = F)| Anfänglich | Extraktion | |
|---|---|---|
| d | 1 | 0.986 |
| l | 1 | 1.000 |
| a | 1 | 0.987 |
| c | 1 | 0.976 |
| v | 1 | 0.970 |
| t | 1 | 0.975 |
Code
| Mittelwert | Std.-Abweichung | Analyse N | |
|---|---|---|---|
| d | 2.0000 | 0.8321 | 27 |
| l | 3.0000 | 0.8321 | 27 |
| a | 3.6652 | 2.6411 | 27 |
| c | 18.8496 | 9.6634 | 27 |
| v | 10.9956 | 8.7594 | 27 |
| t | 3.6973 | 0.8299 | 27 |
- Klick auf den Reiter Analysieren
- im Dropdownmenu Dimensionsreduktion ➡️ Faktorenanalyse… auswählen
- die sechs Variablen (
d,l,a,c,v,t) markieren und mit Klick auf ↪️ zu Variablen hinzufügen - mit Klick auf 🆗 bestätigen oder besser auf Einfügen klicken und die Synatax ausführen
Interpretation
Kommunalitäten
In dem anfänglichen Modell sind gleiche viele Variablen und Faktoren vorhanden, weswegen jede der sechs Variablen perfekt erklärt werden kann. Ihre Kommunalität ist entsprechend 1 (vgl. anfängliche Kommunalitäten).
Die extrahierten Kommunalitäten sind alle \(\small \geq 0.970\), d.h. mit dem zweifaktoriellen Modell lassen sich alle Variablen nahezu perfekt erklären.
erklärte Gesamtvarianz
Analog kann die erklärte Varianz betrachet werden: Vor Extraktion wird (aufkummuliert) 100% der Varianz erklärt. Durch die Reduktion auf zwei Komponenten sind es noch immer 98.24%, d.h. kaum Verlust.
Die erklärte Varianz ergibt sich dabei aus den Eigenwerten (Spalte Gesamt) geteilt durch die Anzahl an Variablen (hier 6)2. Diese Varianz (Spalte % der Varianz) wird dann aufkumuliert.
Ladungs- aka. Komponentenmatrix
Für Faktoranalysen ist die Ladungs- und für Hauptkomponentenanalysen die Komponentenmatrix gemeint. Für die Interpretation siehe Folgeaufgabe.
Teilaufgabe b
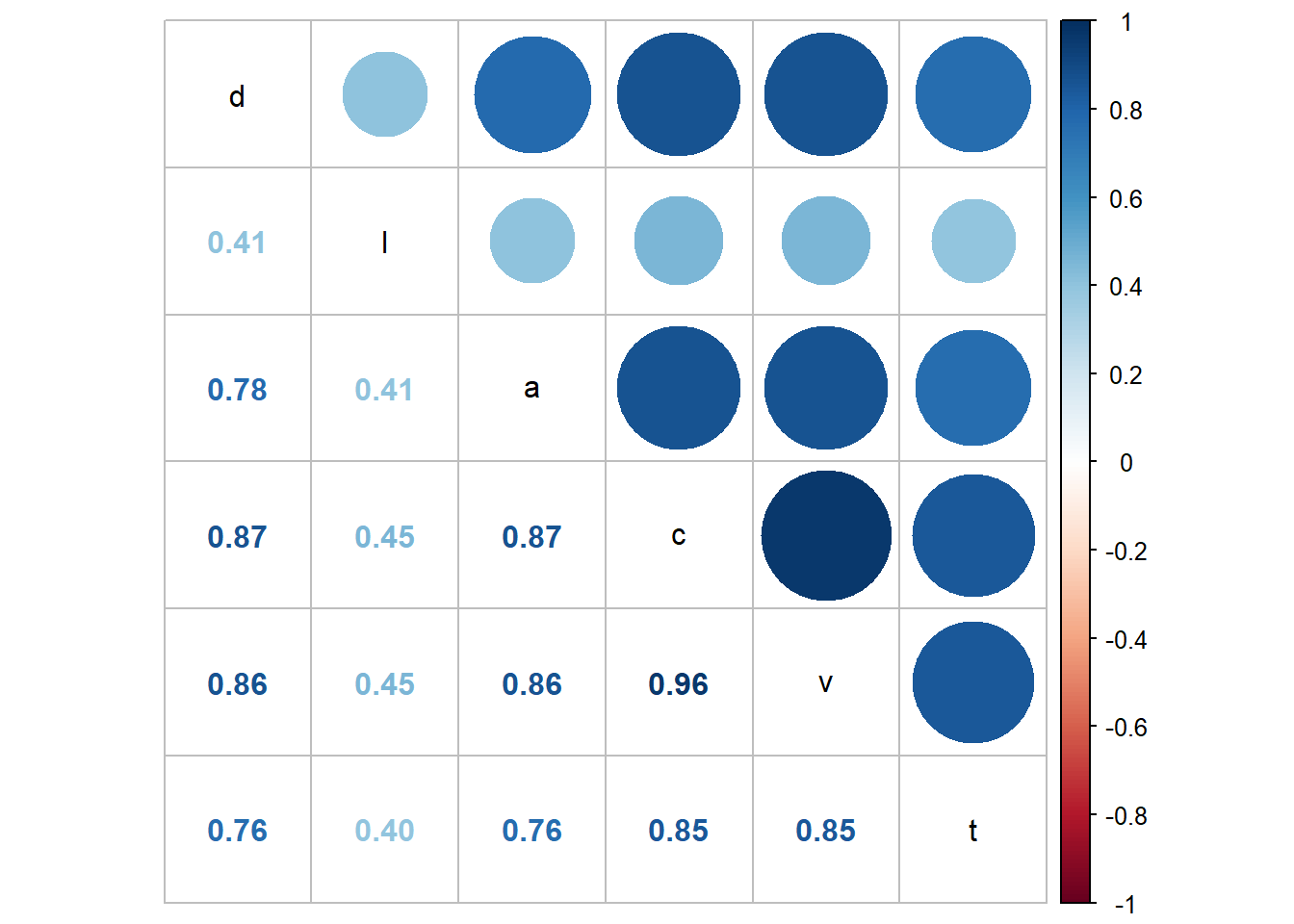
| Komponente | ||
|---|---|---|
| 1 | 2 | |
| d | 0.881 | −0.458 |
| l | 0.461 | 0.887 |
| a | 0.881 | −0.459 |
| c | 0.983 | 0.100 |
| v | 0.978 | −0.115 |
| t | 0.864 | 0.478 |
Durch die farbliche Codierung wird schnell ersichtlich, dass beinahe alle Variablen (mit Ausnahme von l) hoch und positiv mit der ersten Komponente korreliert sind. Umgekehrt ist genau diese Variable als einzige hoch mit Faktor 2 korreliert, die übrigen hingegen nur bedingt. Man sagt, die zweite Komponente läd auf l.
D.h. die Länge bzw. Höhe des Zylinders ist ein eigener Faktor bzw. Komponente. Im Gegensatz dazu steht der Durchmesser d, von welchem auch Grundfläche abhängt. Ebenso sehen wir dies beim Volumen v. Zwar hängt v von beiden Variablen ab, allerdings wissen wir aus der Berechnung, dass d durch dessen Quadiertung einen wesentlich stärkeren Einfluss hat als l, das nur zu einem Viertel einfließt. Entsprechend können auch die übrigen Variablen betrachtet werden.
Insofern beschreiben die Komponenten (1) Form und (2) Größe des Zylinders.
Teilaufgabe c
Code
df_eigen_col %>% pivot_longer(cols = everything(),
names_prefix = "eig") %>%
kbl(booktabs = TRUE,
digits = 3,
align = "c",
col.names = c("Spalte", "Eigenwert")) %>%
kable_paper("hover", full_width = F)| Spalte | Eigenwert |
|---|---|
| 1 | 4.435 |
| 2 | 1.459 |
Teilaufgabe d
Code
| 1 | 2 | Kommunalität | |
|---|---|---|---|
| d | 0.881 | -0.458 | 0.986 |
| l | 0.461 | 0.887 | 1.000 |
| a | 0.881 | -0.459 | 0.987 |
| c | 0.983 | 0.100 | 0.976 |
| v | 0.978 | -0.115 | 0.970 |
| t | 0.864 | 0.478 | 0.975 |
Teilaufgabe e
Es lassen sich so viele Faktoren extrahieren, wie es Variablen gibt:
pca_6 <- principal(df_thurs, nfactors = 6, rotate = "none")
pca_6Principal Components Analysis
Call: principal(r = df_thurs, nfactors = 6, rotate = "none")
Standardized loadings (pattern matrix) based upon correlation matrix
PC1 PC2 PC3 PC4 PC5 PC6 h2 u2 com
d 0.88 -0.46 0.09 -0.08 0.00 0.01 1 4.4e-16 1.5
l 0.46 0.89 0.01 0.00 0.01 0.01 1 3.8e-15 1.5
a 0.88 -0.46 0.09 0.06 0.01 0.00 1 2.2e-16 1.5
c 0.98 0.10 -0.14 -0.06 0.01 -0.01 1 4.4e-16 1.1
v 0.98 -0.12 -0.16 0.06 -0.01 0.00 1 2.2e-16 1.1
t 0.86 0.48 0.16 0.01 -0.01 -0.01 1 1.9e-15 1.6
PC1 PC2 PC3 PC4 PC5 PC6
SS loadings 4.44 1.46 0.09 0.02 0 0
Proportion Var 0.74 0.24 0.01 0.00 0 0
Cumulative Var 0.74 0.98 1.00 1.00 1 1
Proportion Explained 0.74 0.24 0.01 0.00 0 0
Cumulative Proportion 0.74 0.98 1.00 1.00 1 1
Mean item complexity = 1.4
Test of the hypothesis that 6 components are sufficient.
The root mean square of the residuals (RMSR) is 0
with the empirical chi square 0 with prob < NA
Fit based upon off diagonal values = 1Der Versuch mehr Faktoren zu extrahieren führt zu einer Fehlermeldung
principal(df_thurs, nfactors = 7, rotate = "none") Error in loadings[, 1:nfactors] : subscript out of bounds
Teilaufgabe f
pca_1 <- principal(df_thurs, nfactors = 1, rotate = "none", residuals = TRUE)
pca_1$residual
pca_2$residual| d | l | a | c | v | t | |
|---|---|---|---|---|---|---|
| d | 0.224 | -0.406 | 0.213 | -0.054 | 0.033 | -0.206 |
| l | -0.406 | 0.788 | -0.406 | 0.088 | -0.103 | 0.425 |
| a | 0.213 | -0.406 | 0.223 | -0.063 | 0.042 | -0.204 |
| c | -0.054 | 0.088 | -0.063 | 0.035 | 0.007 | 0.025 |
| v | 0.033 | -0.103 | 0.042 | 0.007 | 0.043 | -0.079 |
| t | -0.206 | 0.425 | -0.204 | 0.025 | -0.079 | 0.253 |
| d | l | a | c | v | t | |
|---|---|---|---|---|---|---|
| d | 0.014 | 0.000 | 0.003 | -0.008 | -0.019 | 0.013 |
| l | 0.000 | 0.000 | 0.001 | -0.001 | -0.001 | 0.001 |
| a | 0.003 | 0.001 | 0.013 | -0.017 | -0.011 | 0.015 |
| c | -0.008 | -0.001 | -0.017 | 0.024 | 0.019 | -0.023 |
| v | -0.019 | -0.001 | -0.011 | 0.019 | 0.030 | -0.024 |
| t | 0.013 | 0.001 | 0.015 | -0.023 | -0.024 | 0.025 |
Die Residuen sind für zwei Komponenten augenscheinlich geringer als für nur eine Komponente, wieso es sich lohnt anstatt nur einer zwei Komponenten zu extrahieren. Analog können dazu die reproduzierten Korrelationen betrachtet werden.
Die reproduzierten Korrelationen ergeben sich als Differenz der Korrelationsmatrix und den Residuen des Modells:
| d | l | a | c | v | t | |
|---|---|---|---|---|---|---|
| d | 0.776 | 0.406 | 0.777 | 0.866 | 0.862 | 0.761 |
| l | 0.406 | 0.212 | 0.406 | 0.453 | 0.451 | 0.398 |
| a | 0.777 | 0.406 | 0.777 | 0.866 | 0.862 | 0.762 |
| c | 0.866 | 0.453 | 0.866 | 0.965 | 0.961 | 0.849 |
| v | 0.862 | 0.451 | 0.862 | 0.961 | 0.957 | 0.846 |
| t | 0.761 | 0.398 | 0.762 | 0.849 | 0.846 | 0.747 |
Teilaufgabe g
Der Vektor \(\small \mathbf{a_1}\) ist durch die Ladungen gegeben:
| a1 |
|---|
| 0.881 |
| 0.461 |
| 0.881 |
| 0.983 |
| 0.978 |
| 0.864 |
Entsprechend kann berechnet werden:
\[ \small \begin{align*} \mathbf{a_{1}} \cdot \mathbf{a_{1}}' &= \begin{pmatrix} 0.881 \\ 0.461 \\ 0.881 \\ 0.983 \\ 0.978 \\ 0.864 \end{pmatrix} \cdot \begin{pmatrix} 0.881, & 0.461, & 0.881, & 0.983, & 0.978, & 0.864 \end{pmatrix}\\ \mathbf{a_{1}} \cdot \mathbf{a_{1}}' &= \begin{pmatrix} 0.776, & 0.406, & 0.777, & 0.866, & 0.862, & 0.761\\ \vdots & \ddots \\ &\\&\\\vdots &\\0.761&\cdots \end{pmatrix} \end{align*} \]
Die Richtigkeit unserer Berechnung3 kann leicht überprüft werden:
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 0.776 0.406 0.777 0.866 0.862 0.761
[2,] 0.406 0.212 0.406 0.453 0.451 0.398
[3,] 0.777 0.406 0.777 0.866 0.862 0.762
[4,] 0.866 0.453 0.866 0.965 0.961 0.849
[5,] 0.862 0.451 0.862 0.961 0.957 0.846
[6,] 0.761 0.398 0.762 0.849 0.846 0.747Teilaufgabe h
pca_2_rot <- principal(df_thurs, nfactors = 2, rotate = "varimax")
pca_2_rotPrincipal Components Analysis
Call: principal(r = df_thurs, nfactors = 2, rotate = "varimax")
Standardized loadings (pattern matrix) based upon correlation matrix
RC1 RC2 h2 u2 com
d 0.99 0.05 0.99 0.01424 1.0
l -0.05 1.00 1.00 0.00013 1.0
a 0.99 0.05 0.99 0.01260 1.0
c 0.80 0.58 0.98 0.02450 1.8
v 0.90 0.40 0.97 0.02963 1.4
t 0.50 0.85 0.98 0.02468 1.6
RC1 RC2
SS loadings 3.68 2.22
Proportion Var 0.61 0.37
Cumulative Var 0.61 0.98
Proportion Explained 0.62 0.38
Cumulative Proportion 0.62 1.00
Mean item complexity = 1.3
Test of the hypothesis that 2 components are sufficient.
The root mean square of the residuals (RMSR) is 0.01
with the empirical chi square 0.15 with prob < 1
Fit based upon off diagonal values = 1Die Faktorladungden (vgl. SS loadings) der beiden Faktoren haben sich nach der Rotation (rechts) geändert:
pca_2$Vaccounted PC1 PC2
SS loadings 4.4353191 1.4588962
Proportion Var 0.7392199 0.2431494
Cumulative Var 0.7392199 0.9823692
Proportion Explained 0.7524868 0.2475132
Cumulative Proportion 0.7524868 1.0000000pca_2_rot$Vaccounted RC1 RC2
SS loadings 3.6753495 2.2188659
Proportion Var 0.6125582 0.3698110
Cumulative Var 0.6125582 0.9823692
Proportion Explained 0.6235519 0.3764481
Cumulative Proportion 0.6235519 1.0000000Damit klären beide Komponenten vergleichbare Anteile an Varianz nach Rotation auf.
Ebenso können wir die Ladungsmatrix ohne Rotation (oben erläutert) jener mit Rotation gegenüberstellen:
pca_2$loadings; pca_2_rot$loadings| Komponente | ||
|---|---|---|
| 1 | 2 | |
| d | 0.881 | −0.458 |
| l | 0.461 | 0.887 |
| a | 0.881 | −0.459 |
| c | 0.983 | 0.100 |
| v | 0.978 | −0.115 |
| t | 0.864 | 0.478 |
| Komponente | ||
|---|---|---|
| 1 | 2 | |
| d | 0.992 | 0.050 |
| l | −0.051 | 0.999 |
| a | 0.992 | 0.050 |
| c | 0.797 | 0.583 |
| v | 0.902 | 0.395 |
| t | 0.505 | 0.849 |
Nach der Rotation lassen sich d und l noch klarer der ersten und zweiten Komponente zuordnen.
Fußnoten
ferner wird in der Vorlesung nicht zwischen explorativer und konfirmatorischer FA unterschieden, wobei offensichtlich erstere (nachfolgend) stets gemeint ist↩︎
Um der Angabe in SPSS zu entsprechen, d.h. von relativen Werten auf Prozente zu kommen wurde mit dem Faktor 100 multipliziert↩︎
wurde selbstverständlich wirklich gerechnet 😥 nicht↩︎